



近年来,随着人工智能领域的迅猛发展,大规模预训练语言模型(简称大模型)成为了推动技术进步的核心力量。这些大模型在自然语言处理等任务中展现出了令人惊叹的能力。然而,要准确衡量一个大模型的性能,必须依靠科学而合理的评测。
什么是大模型评测?大模型评测就是通过各种标准化的方法和数据集,对大模型在不同任务上的表现进行量化和比较。这些评测不仅包括模型在特定任务上的准确性,还涉及模型的泛化能力、推理速度、资源消耗等多个方面。通过评测,我们能够更全面地了解大模型的实际表现,以及它们在现实世界中的应用潜力。
大模型的开发成本高昂,涉及大量的计算资源和数据,因此评测对于确保模型的实际价值至关重要。首先,评测能够揭示模型在各种任务中的表现,帮助研究人员和企业判断模型的适用性和可靠性。其次,评测可以暴露模型的潜在弱点,例如偏见、鲁棒性问题等,从而为进一步优化和改进提供依据。此外,公平、公开的评测还为学术界和工业界提供了一个共同的标准,促进了技术的交流与进步。
7.1.1 LLM 的评测数据集
在大模型的评测过程中,使用标准化的评测集至关重要。目前,主流的大模型评测集主要从以下几个方面进行评估,每个评测集都有其独特的用途和典型应用场景:
通用评测集:
MMLU(Massive Multitask Language Understanding):MMLU评测模型在多种任务中的理解能力,包括各类学科和知识领域。具体包含了历史、数学、物理、生物、法律等任务类型,全面考察模型在不同学科的知识储备和语言理解能力。
工具使用评测集:
BFCL V2:用于评测模型在复杂工具使用任务中的表现,特别是在执行多步骤操作时的正确性和效率。这些任务通常涉及与数据库交互或执行特定指令,以模拟实际工具使用场景。
数学评测集:
GSM8K:GSM8K是一个包含小学数学问题的数据集,用于测试模型的数学推理和逻辑分析能力。具体任务包括算术运算、简单方程求解、数字推理等。GSM8K中的问题虽然看似简单,但模型需要理解问题语义并进行正确的数学运算,体现了逻辑推理和语言理解的双重挑战。
MATH:MATH数据集用于测试模型在更复杂的数学问题上的表现,包括代数和几何。
推理评测集:
ARC Challenge:ARC Challenge评测模型在科学推理任务中的表现,尤其是常识性和科学性问题的解答,典型应用场景包括科学考试题解答和百科问答系统的开发。
GPQA:用于评测模型在零样本条件下对开放性问题的回答能力,通常应用于客服聊天机器人和知识问答系统中,帮助模型在缺乏特定领域数据的情况下给出合理的回答。
HellaSwag:评测模型在复杂语境下选择最符合逻辑的答案的能力,适用于故事续写、对话生成等需要高水平理解和推理的场景。
长文本理解评测集:
InfiniteBench/En.MC:评测模型在处理长文本阅读理解方面的能力,尤其是对科学文献的理解,适用于学术文献自动摘要、长篇报道分析等应用场景。
NIH/Multi-needle:用于测试模型在多样本长文档环境中的理解和总结能力,应用于政府报告解读、企业内部长文档分析等需要处理海量信息的场景。
多语言评测集:
MGSM:用于评估模型在不同语言下的数学问题解决能力,考察模型的多语言适应性,尤其适用于国际化环境中的数学教育和跨语言技术支持场景。
这些评测集的多样性帮助我们全面评估大模型在不同任务和应用场景中的表现,确保模型在处理多样化任务时能够保持高效和精准的表现。例如,在MMLU评测中,某些大模型在历史、物理等学科任务中表现优异,展现出对多领域知识的深度理解;在GSM8K数学评测中,最新的大模型在算术和方程求解方面表现接近甚至超越了一些人类基准,显示出在复杂数学推理任务中的潜力。这些实际评测结果展示了模型在各类复杂任务中的进步和应用潜力。
7.1.2 主流的评测榜单
大模型的评测不仅限于使用特定的数据集,许多机构还会根据评测结果发布模型排行榜,这些榜单为学术界和工业界提供了重要的参考,帮助他们了解当前最前沿的技术和模型。以下是一些主流的评测榜单:
Open LLM Leaderboard
Open LLM Leaderboard 为由 Hugging Face 提供的开放式榜单,汇集了多个开源大模型的评测结果,帮助用户了解不同模型在各种任务上的表现。该榜单通过多个标准化测试集来评估模型的性能,并通过持续更新的方式反映最新的技术进展,为研究者和开发者提供了高价值的对比参考,如图7.1所示。
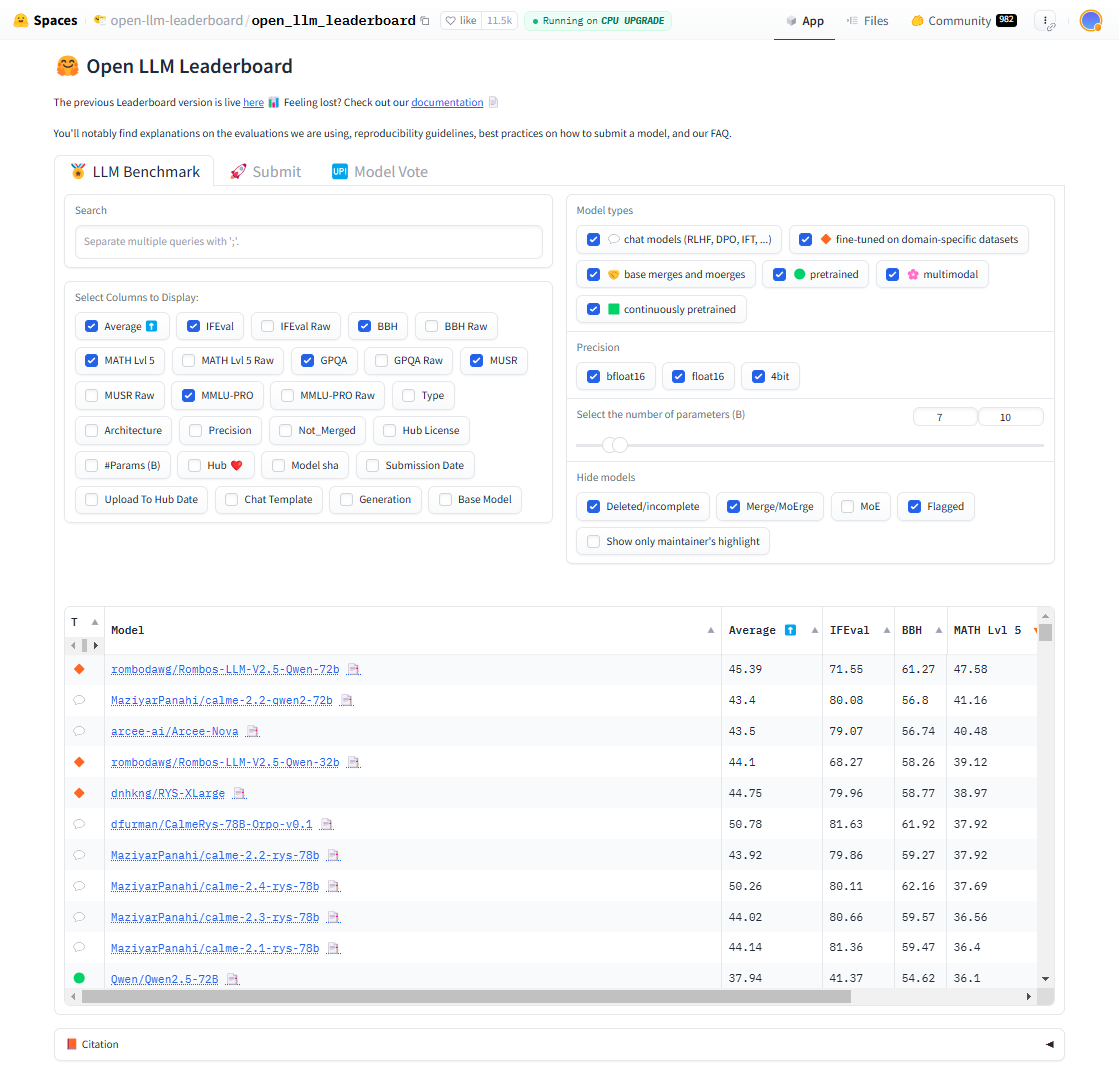
图 7.1 Open LLM Leaderboard
Lmsys Chatbot Arena Leaderboard
由lmsys提供的聊天机器人评测榜单,通过多维度的评估,展示各类大模型在对话任务中的能力。该榜单采用真实用户与模型交互的方式来评测对话质量,重点考察模型的自然语言生成能力、上下文理解能力以及用户满意度,是当前评估聊天机器人性能的重要工具,如图7.2所示。
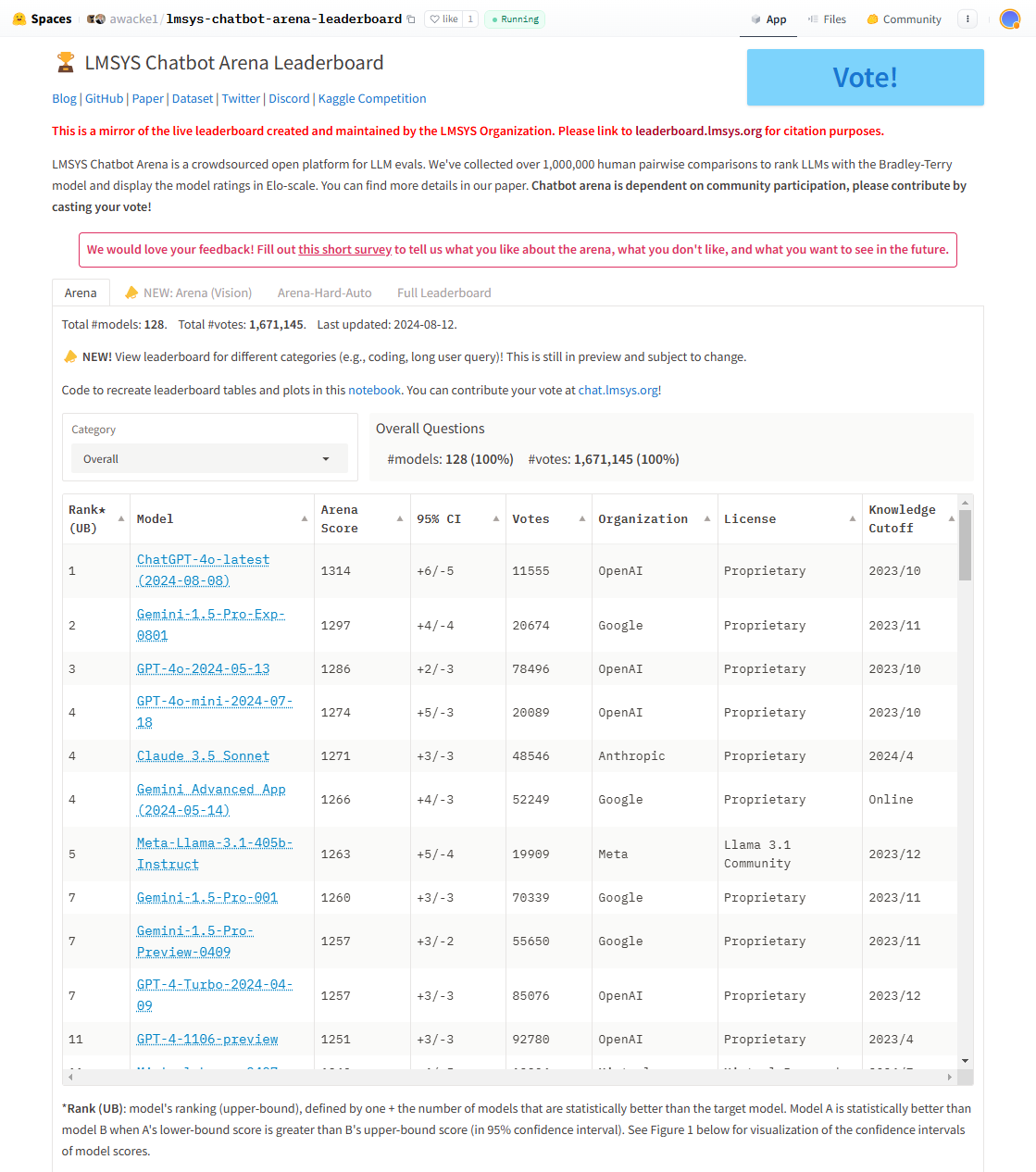
图7.2 Lmsys Chatbot Arena Leaderboard
OpenCompass
OpenCompass 是国内的评测榜单,针对大模型在多种语言和任务上的表现进行评估,提供了中国市场特定应用的参考。该榜单结合了中文语言理解和多语言能力的测试,以适应本地化需求,并特别关注大模型在中文语境下的准确性、鲁棒性和适应性,为国内企业和研究者选择合适的模型提供了重要参考。
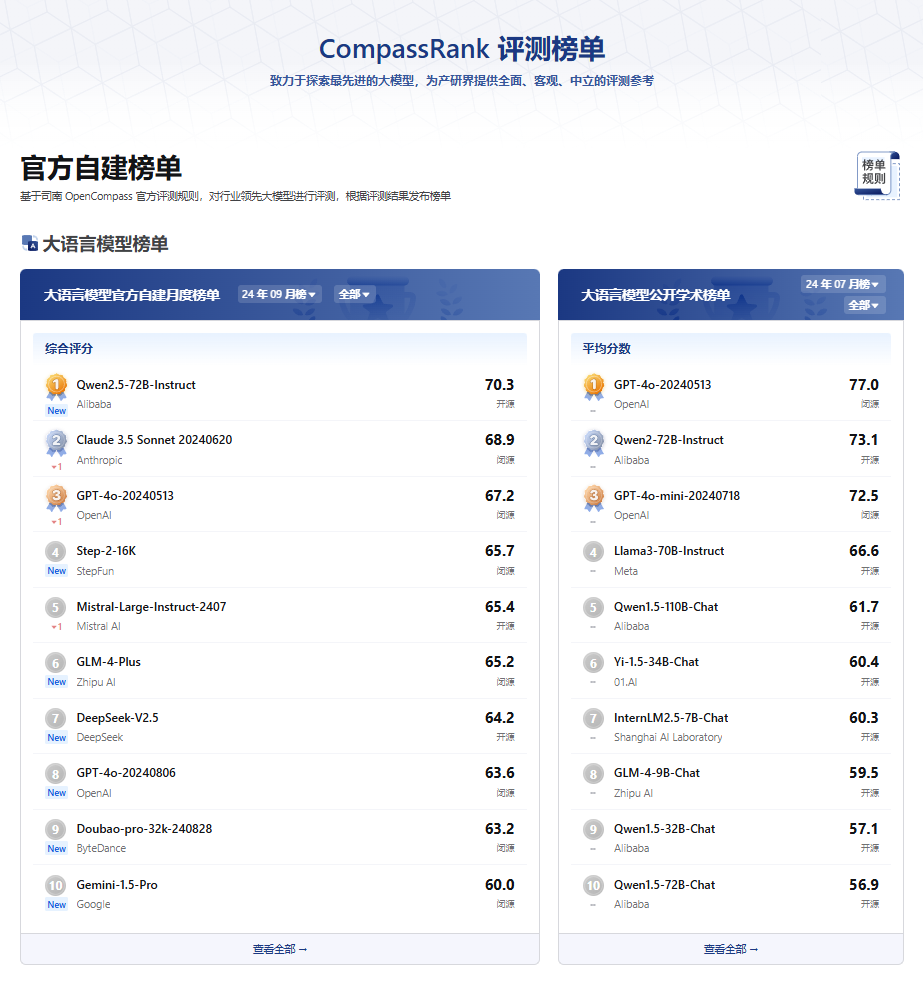
图7.3 OpenCompass
7.1.3 特定的评测榜单
另外,还有针对不同领域特定任务的大模型评测榜单,如图7.4所示。这些榜单专注于特定应用领域,帮助用户了解大模型在某一垂直领域的能力:
金融榜:基于CFBenchmark评测集,评估大模型在金融自然语言处理、金融预测计算、金融分析与安全检查等多项基础任务中的能力。由同济大学与上海人工智能实验室及东方财经提供。
安全榜:基于Flames评测集,评估大模型在公平、安全、数据保护以及合法五大维度的抗性,帮助深入了解模型在安全性上的表现。由上海人工智能实验室与复旦大学提供。
通识榜:基于BotChat评测集,评估大语言模型生成日常多轮对话能力的综合程度,判断模型在对话中是否具备类人水平。由上海人工智能实验室提供。
法律榜:基于LawBench评测集,评估模型在法律领域的理解、推理和应用能力,涵盖法律问题回答、文本生成、法律判例分析等任务。由南京大学提供。
医疗榜:基于MedBench评测集,评估大语言模型在医学知识问答、安全伦理理解等方面的表现。由上海人工智能实验室提供。

图7.4 垂直领域榜单
7.2 RAG
7.2.1 RAG 的基本原理
大语言模型(LLM)在生成内容时,虽然具备强大的语言理解和生成能力,但也面临着一些挑战。例如,LLM有时会生成不准确或误导性的内容,这被称为大模型“幻觉”。此外,模型所依赖的训练数据可能过时,尤其在面对最新的信息时,生成结果的准确性和时效性难以保证。对于特定领域的专业知识,LLM 的处理效率也较低,无法深入理解复杂的领域知识。因此,如何提升大模型的生成质量和效率,成为了当前研究的重要方向。
在这样的背景下,检索增强生成(Retrieval-Augmented Generation,RAG)技术应运而生,成为AI领域中的一大创新趋势。RAG 在生成答案之前,首先从外部的大规模文档数据库中检索出相关信息,并将这些信息融入到生成过程之中,从而指导和优化语言模型的输出。这一流程不仅极大地提升了内容生成的准确性和相关性,还使得生成的内容更加符合实时性要求。
RAG 的核心原理在于将“检索”与“生成”结合:当用户提出查询时,系统首先通过检索模块找到与问题相关的文本片段,然后将这些片段作为附加信息传递给语言模型,模型据此生成更为精准和可靠的回答。通过这种方式,RAG 有效缓解了大语言模型的“幻觉”问题,因为生成的内容建立在真实文档的基础上,使得答案更具可追溯性和可信度。同时,由于引入了最新的信息源,RAG 技术大大加快了知识更新速度,使得系统可以及时吸收和反映最新的领域动态。
7.2.2 搭建一个 RAG 框架
接下来我会带领大家一步一步实现一个简单的RAG模型,这个模型是基于RAG的一个简化版本,我们称之为 Tiny-RAG 。Tiny-RAG只保留了 RAG 的核心功能,即检索和生成,其目的是帮助大家更好地理解 RAG 模型的原理和实现。
Step 1: RAG流程介绍
RAG通过在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程,从而极大地提升了内容的准确性和相关性。RAG有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大型语言模型在实际应用中变得更加实用和可信。
RAG的基本结构有哪些呢?
向量化模块:用来将文档片段向量化。
文档加载和切分模块:用来加载文档并切分成文档片段。
数据库:存放文档片段及其对应的向量表示。
检索模块:根据 Query(问题)检索相关的文档片段。
大模型模块:根据检索到的文档回答用户的问题。
上述也就是 TinyRAG 的所有模块内容,如图7.5所示。
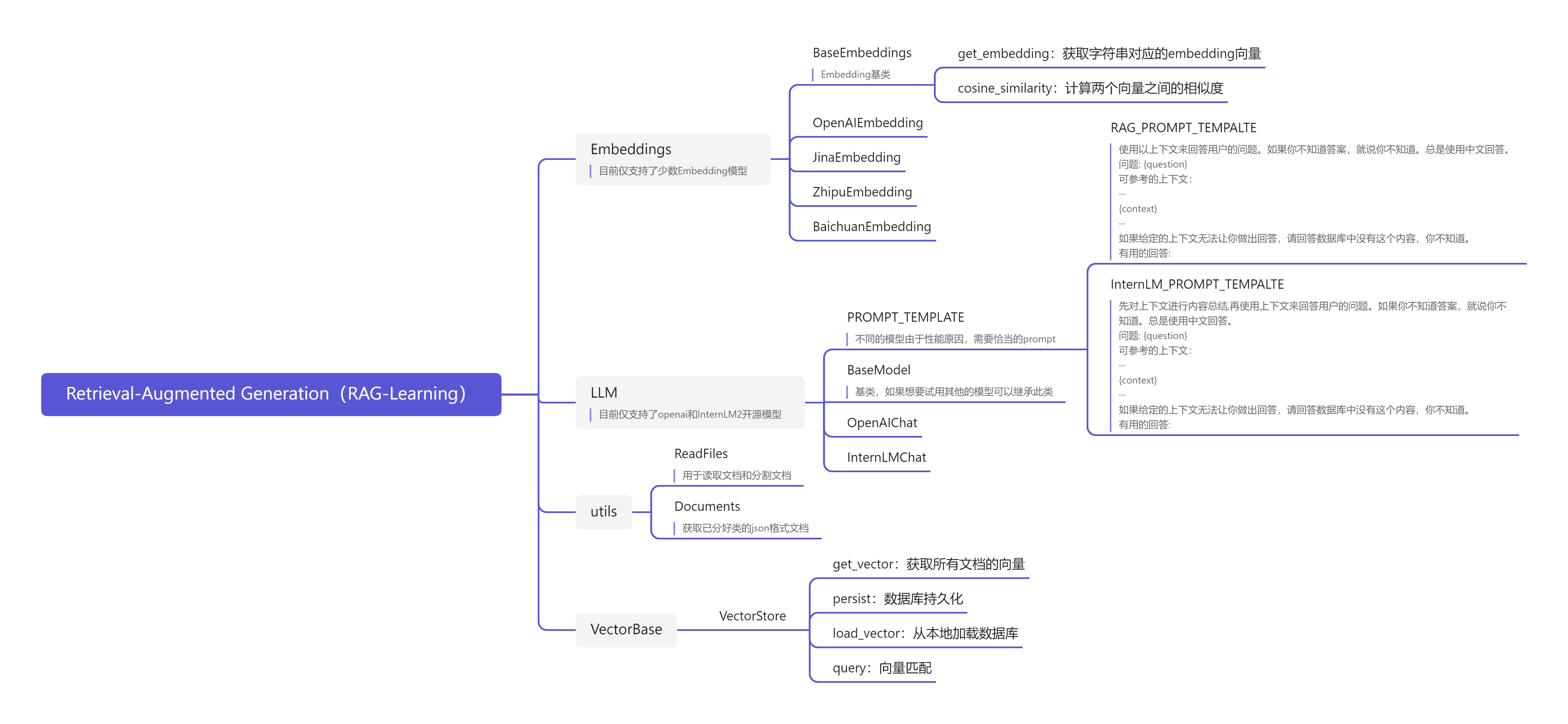
图7.5 TinyRAG 项目结构
接下来,让我们梳理一下RAG的流程是什么样的呢?
索引:将文档库分割成较短的片段,并通过编码器构建向量索引。
检索:根据问题和片段的相似度检索相关文档片段。
生成:以检索到的上下文为条件,生成问题的回答。
如下图7.6所示的流程图,图片出处 Retrieval-Augmented Generation for Large Language Models: A Survey
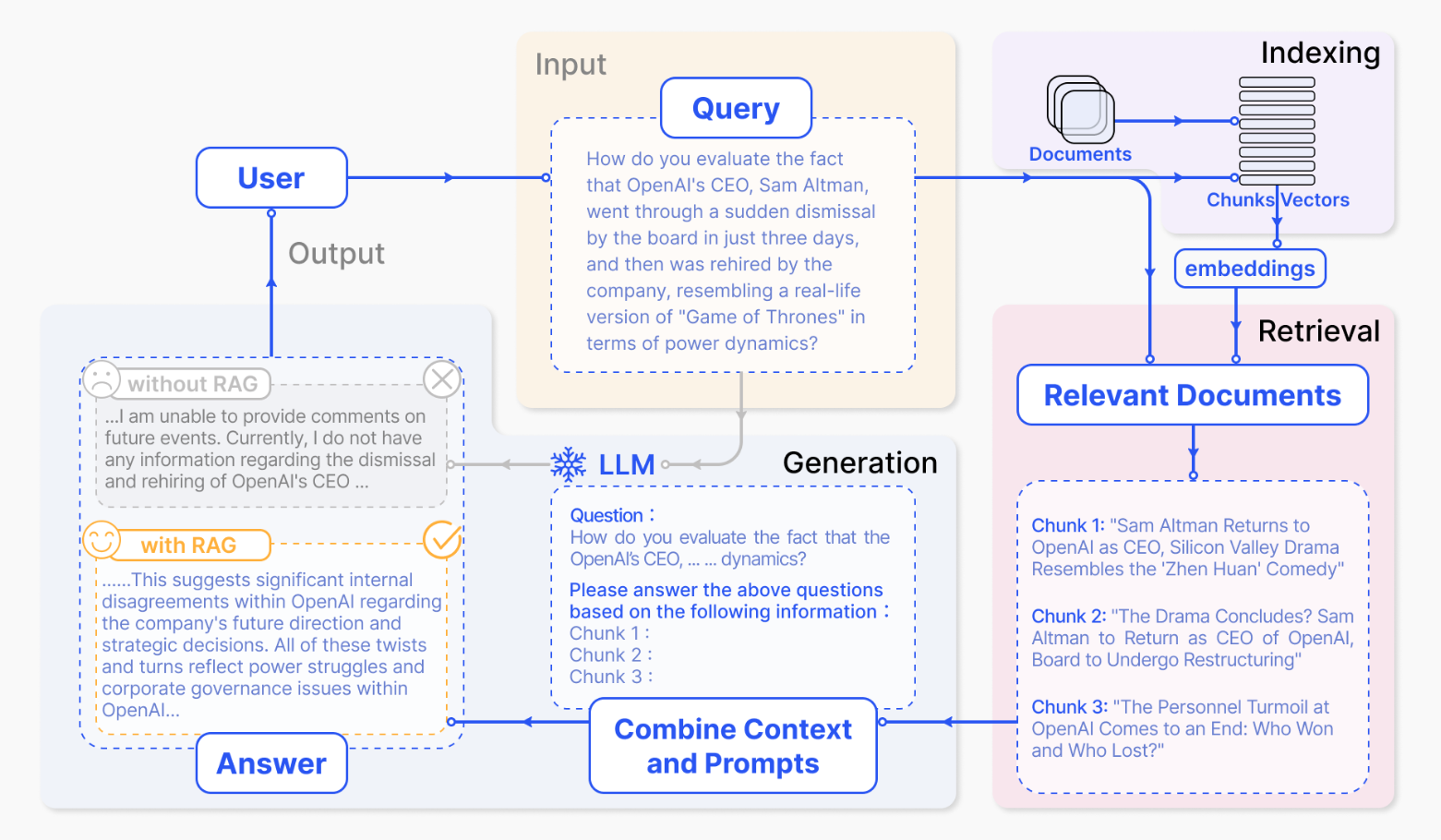
图7.6 RAG 流程图
Step 2: 文档加载和切分
接下来我们来实现一个文档加载和切分的类,这个类主要用于加载文档并将其切分成文档片段。
文档可以是文章、书籍、对话、代码等文本内容,例如pdf文件、md文件、txt文件等。完整代码可以在 RAG/utils.py 文件中找到。该代码支持加载pdf、md、txt等类型的文件,只需编写相应的函数即可。
def read_file_content(cls, file_path: str):
# 根据文件扩展名选择读取方法
if file_path.endswith('.pdf'):
return cls.read_pdf(file_path)
elif file_path.endswith('.md'):
return cls.read_markdown(file_path)
elif file_path.endswith('.txt'):
return cls.read_text(file_path)
else:
raise ValueError("Unsupported file type")文档读取后需要进行切分。我们可以设置一个最大的Token长度,然后根据这个最大长度来切分文档。切分文档时最好以句子为单位(按\n粗切分),并保证片段之间有一些重叠内容,以提高检索的准确性。
def get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):
chunk_text = []
curr_len = 0
curr_chunk = ''
token_len = max_token_len - cover_content
lines = text.splitlines() # 假设以换行符分割文本为行
for line in lines:
# 保留空格,只移除行首行尾空格
line = line.strip()
line_len = len(enc.encode(line))
if line_len > max_token_len:
# 如果单行长度就超过限制,则将其分割成多个块
# 先保存当前块(如果有内容)
if curr_chunk:
chunk_text.append(curr_chunk)
curr_chunk = ''
curr_len = 0
# 将长行按token长度分割
line_tokens = enc.encode(line)
num_chunks = (len(line_tokens) + token_len - 1) // token_len
for i in range(num_chunks):
start_token = i * token_len
end_token = min(start_token + token_len, len(line_tokens))
# 解码token片段回文本
chunk_tokens = line_tokens[start_token:end_token]
chunk_part = enc.decode(chunk_tokens)
# 添加覆盖内容(除了第一个块)
if i > 0 and chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunk
chunk_part = cover_part + chunk_part
chunk_text.append(chunk_part)
# 重置当前块状态
curr_chunk = ''
curr_len = 0
elif curr_len + line_len + 1 <= token_len: # +1 for newline
# 当前行可以加入当前块
if curr_chunk:
curr_chunk += '\n'
curr_len += 1
curr_chunk += line
curr_len += line_len
else:
# 当前行无法加入当前块,开始新块
if curr_chunk:
chunk_text.append(curr_chunk)
# 开始新块,添加覆盖内容
if chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunk
curr_chunk = cover_part + '\n' + line
curr_len = len(enc.encode(cover_part)) + 1 + line_len
else:
curr_chunk = line
curr_len = line_len
# 添加最后一个块(如果有内容)
if curr_chunk:
chunk_text.append(curr_chunk)
return chunk_textStep 3: 向量化
首先我们来动手实现一个向量化的类,这是RAG架构的基础。向量化类主要用来将文档片段向量化,将一段文本映射为一个向量。
首先我们要设置一个 BaseEmbeddings 基类,这样我们在使用其他模型时,只需要继承这个基类,然后在此基础上进行修改即可,方便代码扩展。
class BaseEmbeddings:
"""
Base class for embeddings
"""
def __init__(self, path: str, is_api: bool) -> None:
"""
初始化嵌入基类
Args:
path (str): 模型或数据的路径
is_api (bool): 是否使用API方式。True表示使用在线API服务,False表示使用本地模型
"""
self.path = path
self.is_api = is_api
def get_embedding(self, text: str, model: str) -> List[float]:
"""
获取文本的嵌入向量表示
Args:
text (str): 输入文本
model (str): 使用的模型名称
Returns:
List[float]: 文本的嵌入向量
Raises:
NotImplementedError: 该方法需要在子类中实现
"""
raise NotImplementedError
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
计算两个向量之间的余弦相似度
Args:
vector1 (List[float]): 第一个向量
vector2 (List[float]): 第二个向量
Returns:
float: 两个向量的余弦相似度,范围在[-1,1]之间
"""
# 将输入列表转换为numpy数组,并指定数据类型为float32
v1 = np.array(vector1, dtype=np.float32)
v2 = np.array(vector2, dtype=np.float32)
# 检查向量中是否包含无穷大或NaN值
if not np.all(np.isfinite(v1)) or not np.all(np.isfinite(v2)):
return 0.0
# 计算向量的点积
dot_product = np.dot(v1, v2)
# 计算向量的范数(长度)
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
# 计算分母(两个向量范数的乘积)
magnitude = norm_v1 * norm_v2
# 处理分母为0的特殊情况
if magnitude == 0:
return 0.0
# 返回余弦相似度
return dot_product / magnitudeBaseEmbeddings基类有两个主要方法:get_embedding和cosine_similarity。get_embedding用于获取文本的向量表示,cosine_similarity用于计算两个向量之间的余弦相似度。在初始化类时设置了模型的路径和是否是API模型,例如使用OpenAI的Embedding API需要设置self.is_api=True。
继承BaseEmbeddings类只需要实现get_embedding方法,cosine_similarity方法会被继承下来。这就是编写基类的好处。
class OpenAIEmbedding(BaseEmbeddings):
"""
class for OpenAI embeddings
"""
def __init__(self, path: str = '', is_api: bool = True) -> None:
super().__init__(path, is_api)
if self.is_api:
self.client = OpenAI()
# 从环境变量中获取 硅基流动 密钥
self.client.api_key = os.getenv("OPENAI_API_KEY")
# 从环境变量中获取 硅基流动 的基础URL
self.client.base_url = os.getenv("OPENAI_BASE_URL")
def get_embedding(self, text: str, model: str = "BAAI/bge-m3") -> List[float]:
"""
此处默认使用轨迹流动的免费嵌入模型 BAAI/bge-m3
"""
if self.is_api:
text = text.replace("\n", " ")
return self.client.embeddings.create(input=[text], model=model).data[0].embedding
else:
raise NotImplementedError注:此处我们默认使用国内用户可访问的硅基流动大模型API服务平台。
Step 4: 数据库与向量检索
完成文档切分和Embedding模型加载后,需要设计一个向量数据库来存放文档片段和对应的向量表示,以及设计一个检索模块用于根据Query检索相关文档片段。
向量数据库的功能包括:
persist:数据库持久化保存。load_vector:从本地加载数据库。get_vector:获取文档的向量表示。query:根据问题检索相关文档片段。
完整代码可以在 /VectorBase.py 文件中找到。
class VectorStore:
def __init__(self, document: List[str] = ['']) -> None:
self.document = document
def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:
# 获得文档的向量表示
pass
def persist(self, path: str = 'storage'):
# 数据库持久化保存
pass
def load_vector(self, path: str = 'storage'):
# 从本地加载数据库
pass
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
# 根据问题检索相关文档片段
passquery 方法用于将用户提出的问题向量化,然后在数据库中检索相关文档片段并返回结果。
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
query_vector = EmbeddingModel.get_embedding(query)
result = np.array([self.get_similarity(query_vector, vector) for vector in self.vectors])
return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()Step 5: 大模型模块
接下来是大模型模块,用于根据检索到的文档回答用户的问题。
首先实现一个基类,这样可以方便扩展其他模型。
class BaseModel:
def __init__(self, path: str = '') -> None:
self.path = path
def chat(self, prompt: str, history: List[dict], content: str) -> str:
pass
def load_model(self):
passBaseModel 包含两个方法:chat和load_model。对于本地化运行的开源模型需要实现load_model,而API模型则不需要。在此处我们还是使用国内用户可访问的硅基流动大模型API服务平台,使用API服务的好处就是用户不需要本地的计算资源,可以大大降低学习者的学习门槛。
from openai import OpenAI
class OpenAIChat(BaseModel):
def __init__(self, model: str = "Qwen/Qwen2.5-32B-Instruct") -> None:
self.model = model
def chat(self, prompt: str, history: List[dict], content: str) -> str:
client = OpenAI()
client.api_key = os.getenv("OPENAI_API_KEY")
client.base_url = os.getenv("OPENAI_BASE_URL")
history.append({'role': 'user', 'content': RAG_PROMPT_TEMPLATE.format(question=prompt, context=content)})
response = client.chat.completions.create(
model=self.model,
messages=history,
max_tokens=2048,
temperature=0.1
)
return response.choices[0].message.content设计一个专用于RAG的大模型提示词,如下:
RAG_PROMPT_TEMPLATE="""
使用以上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:
"""这样我们就可以利用InternLM2模型来做RAG啦!
Step 6: Tiny-RAG Demo
接下来,我们来看看Tiny-RAG的Demo吧!
from VectorBase import VectorStore
from utils import ReadFiles
from LLM import OpenAIChat
from Embeddings import OpenAIEmbedding
# 没有保存数据库
docs = ReadFiles('./data').get_content(max_token_len=600, cover_content=150) # 获得data目录下的所有文件内容并分割
vector = VectorStore(docs)
embedding = OpenAIEmbedding() # 创建EmbeddingModel
vector.get_vector(EmbeddingModel=embedding)
vector.persist(path='storage') # 将向量和文档内容保存到storage目录下,下次再用就可以直接加载本地的数据库
# vector.load_vector('./storage') # 加载本地的数据库
question = 'RAG的原理是什么?'
content = vector.query(question, EmbeddingModel=embedding, k=1)[0]
chat = OpenAIChat(model='Qwen/Qwen2.5-32B-Instruct')
print(chat.chat(question, [], content))也可以从本地加载已处理好的数据库:
from VectorBase import VectorStore
from utils import ReadFiles
from LLM import OpenAIChat
from Embeddings import OpenAIEmbedding
# 保存数据库之后
vector = VectorStore()
vector.load_vector('./storage') # 加载本地的数据库
question = 'RAG的原理是什么?'
embedding = ZhipuEmbedding() # 创建EmbeddingModel
content = vector.query(question, EmbeddingModel=embedding, k=1)[0]
chat = OpenAIChat(model='Qwen/Qwen2.5-32B-Instruct')
print(chat.chat(question, [], content))注:7.2 章节的所有代码均可在 Happy-LLM Chapter7 RAG 中找到。
7.3 Agent
7.3.1 什么是 LLM Agent?
简单来说,大模型Agent是一个以LLM为核心“大脑”,并赋予其自主规划、记忆和使用工具能力的系统。 它不再仅仅是被动地响应用户的提示(Prompt),而是能够:
理解目标(Goal Understanding): 接收一个相对复杂或高层次的目标(例如,“帮我规划一个周末去北京的旅游行程并预订机票酒店”)。
自主规划(Planning): 将大目标分解成一系列可执行的小步骤(例如,“搜索北京景点”、“查询天气”、“比较机票价格”、“查找合适的酒店”、“调用预订API”等)。
记忆(Memory): 拥有短期记忆(记住当前任务的上下文)和长期记忆(从过去的交互或外部知识库中学习和检索信息)。
工具使用(Tool Use): 调用外部API、插件或代码执行环境来获取信息(如搜索引擎、数据库)、执行操作(如发送邮件、预订服务)或进行计算。
反思与迭代(Reflection & Iteration): (在更高级的Agent中)能够评估自己的行为和结果,从中学习并调整后续计划。
传统的LLM像一个知识渊博但只能纸上谈兵的图书馆员,而 LLM Agent 则更像一个全能的私人助理,不仅懂得多,还能跑腿办事,甚至能主动思考最优方案。
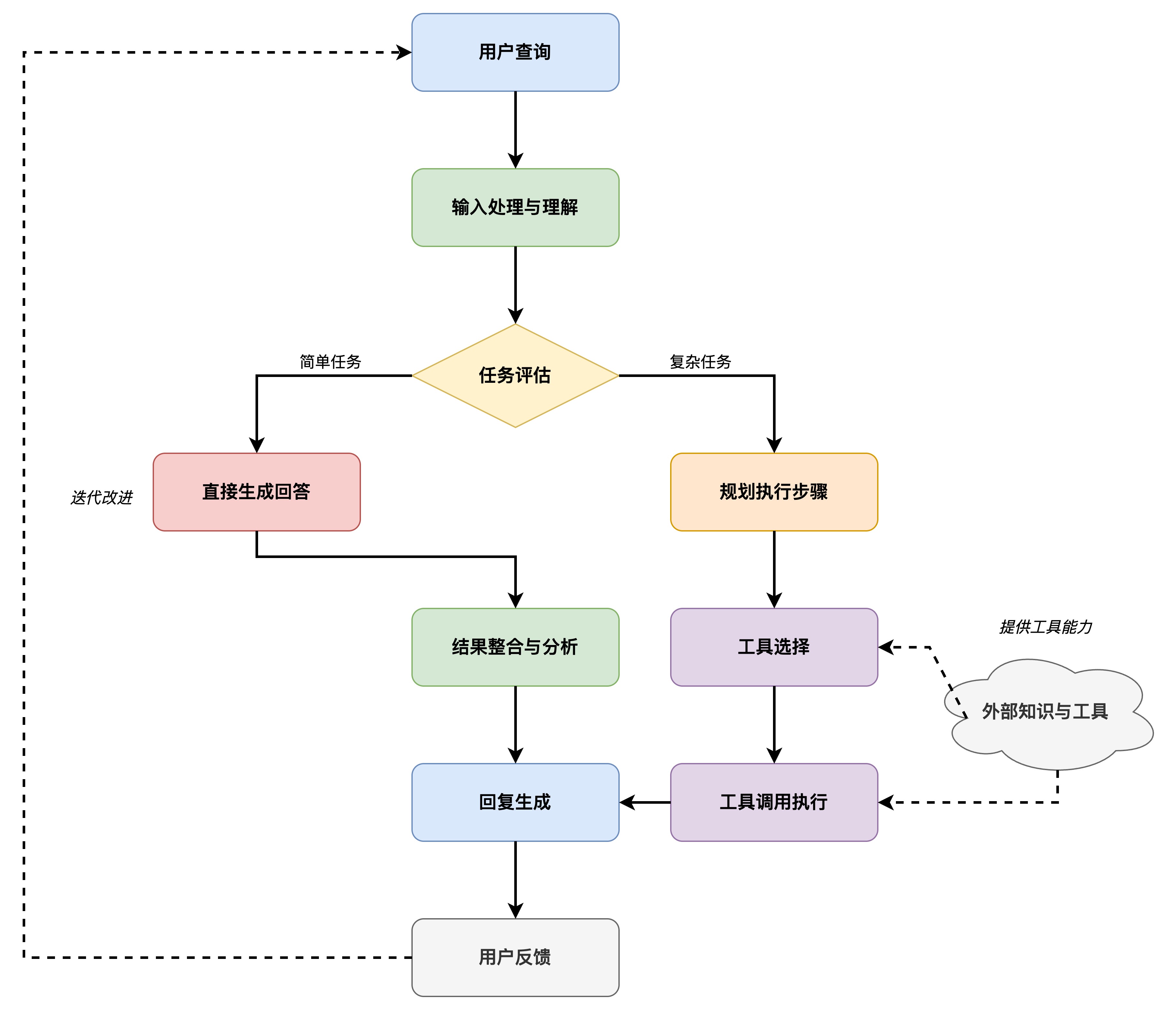
图7.7 Agent 工作原理
LLM Agent 通过将大型语言模型的强大语言理解和生成能力与规划、记忆和工具使用等关键模块相结合,实现了超越传统大模型的自主性和复杂任务处理能力,这种能力使得 LLM Agent 在许多垂直领域(如法律、医疗、金融等)都具有广泛的应用潜力,如图7.7所示 Agent 工作原理。
7.3.2 LLM Agent 的类型
虽然LLM Agent的概念还在快速发展中,但根据其设计理念和能力侧重,我们可以大致将其分为几类:
任务导向型Agent(Task-Oriented Agents):
特点: 专注于完成特定领域的、定义明确的任务,例如客户服务、代码生成、数据分析等。
工作方式: 通常有预设的流程和可调用的特定工具集。LLM主要负责理解用户意图、填充任务槽位、生成回应或调用合适- 的工具。
例子: 专门用于预订餐厅的聊天机器人、辅助编程的代码助手(如GitHub Copilot在某些高级功能上体现了Agent特性)。
规划与推理型Agent(Planning & Reasoning Agents):
特点: 强调自主分解复杂任务、制定多步计划,并根据环境反馈进行调整的能力。它们通常需要更强的推理能力。
工作方式: 常采用特定的思维框架,如ReAct (Reason+Act),让模型先进行“思考”(Reasoning)分析当前情况和所需行动,然后执行“行动”(Action)调用工具,再根据工具返回结果进行下一轮思考。Chain-of-Thought (CoT) 等提示工程技术也是其推理的基础。
例子: 需要整合网络搜索、计算器、数据库查询等多种工具来回答复杂问题的研究型Agent,或者能够自主完成“写一篇关于XX主题的报告,并配上相关数据图表”这类任务的Agent。
多Agent系统(Multi-Agent Systems):
特点: 由多个具有不同角色或能力的Agent协同工作,共同完成一个更宏大的目标。
工作方式: Agent之间可以进行通信、协作、辩论甚至竞争。例如,一个Agent负责规划,一个负责执行,一个负责审查。
例子: 模拟软件开发团队(产品经理Agent、程序员Agent、测试员Agent)来自动生成和测试代码;模拟一个公司组织结构来完成商业策划。AutoGen、ChatDev等框架支持这类系统的构建。
探索与学习型Agent(Exploration & Learning Agents):
特点: 这类Agent不仅执行任务,还能在与环境的交互中主动学习新知识、新技能或优化自身策略,类似于强化学习中的Agent概念。
工作方式: 可能包含更复杂的记忆和反思机制,能够根据成功或失败的经验调整未来的规划和行动。
例子: 能在未知软件环境中自主探索学习如何操作的Agent,或者在玩游戏时不断提升策略的Agent。
7.3.3 动手构造一个 Tiny-Agent
我们来基于 openai 库和其 tool_calls 功能,动手构造一个 Tiny-Agent,这个 Agent 是一个简单的任务导向型 Agent,它能够根据用户的输入,回答一些简单的问题。
最终的实现效果如图7.8所示:
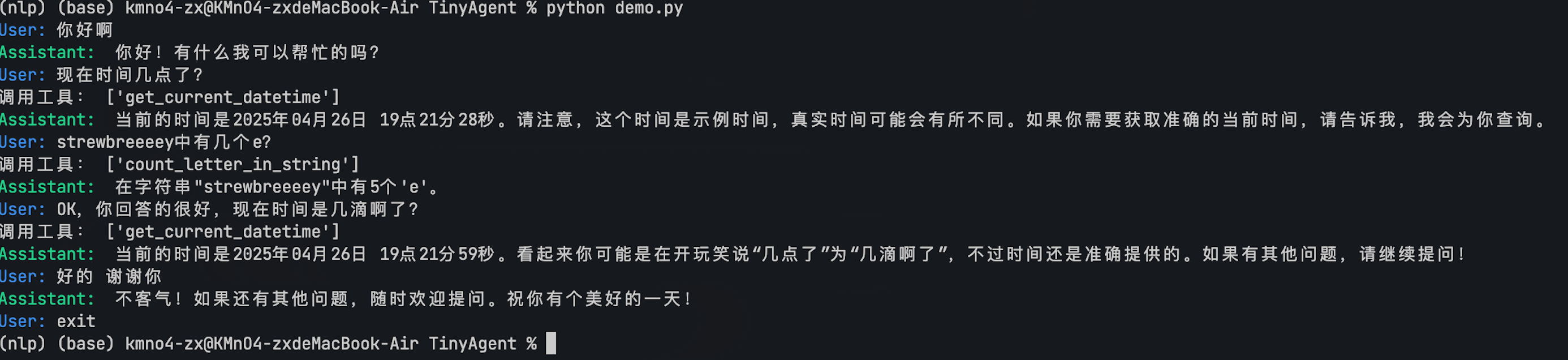
图7.8 效果示意图
Step 1 : 初始化客户端和模型
首先,我们需要一个能够调用大模型的客户端。这里我们使用 openai 库,并配置其指向一个兼容 OpenAI API 的服务终端,例如 SiliconFlow。同时,指定要使用的模型,如 Qwen/Qwen2.5-32B-Instruct。
from openai import OpenAI
# 初始化 OpenAI 客户端
client = OpenAI(
api_key="YOUR_API_KEY", # 替换为你的 API Key
base_url="https://api.siliconflow.cn/v1", # 使用 SiliconFlow 的 API 地址
)
# 指定模型名称
model_name = "Qwen/Qwen2.5-32B-Instruct"注意: 你需要将
YOUR_API_KEY替换为你从 SiliconFlow 或其他服务商获取的有效 API Key。
Step 2: 定义工具函数
我们在 src/tools.py 文件中定义 Agent 可以使用的工具函数。每个函数都需要有清晰的文档字符串(docstring),描述其功能和参数,因为这将用于自动生成工具的 JSON Schema。
# src/tools.py
from datetime import datetime
# 获取当前日期和时间
def get_current_datetime() -> str:
"""
获取当前日期和时间。
:return: 当前日期和时间的字符串表示。
"""
current_datetime = datetime.now()
formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
return formatted_datetime
def count_letter_in_string(a: str, b: str):
"""
统计字符串中某个字母的出现次数。
:param a: 要搜索的字符串。
:param b: 要统计的字母。
:return: 字母在字符串中出现的次数。
"""
return str(a.count(b))
def search_wikipedia(query: str) -> str:
"""
在维基百科中搜索指定查询的前三个页面摘要。
:param query: 要搜索的查询字符串。
:return: 包含前三个页面摘要的字符串。
"""
page_titles = wikipedia.search(query)
summaries = []
for page_title in page_titles[: 3]: # 取前三个页面标题
try:
# 使用 wikipedia 模块的 page 函数,获取指定标题的维基百科页面对象。
wiki_page = wikipedia.page(title=page_title, auto_suggest=False)
# 获取页面摘要
summaries.append(f"页面: {page_title}\n摘要: {wiki_page.summary}")
except (
wikipedia.exceptions.PageError,
wikipedia.exceptions.DisambiguationError,
):
pass
if not summaries:
return "维基百科没有搜索到合适的结果"
return "\n\n".join(summaries)
# ... (可能还有其他工具函数)为了让 OpenAI API 理解这些工具,我们需要将它们转换成特定的 JSON Schema 格式。这可以通过 src/utils.py 中的 function_to_json 辅助函数完成。
# src/utils.py (部分)
import inspect
def function_to_json(func) -> dict:
# ... (函数实现细节)
# 返回符合 OpenAI tool schema 的字典
return {
"type": "function",
"function": {
"name": func.__name__,
"description": inspect.getdoc(func),
"parameters": {
"type": "object",
"properties": parameters,
"required": required,
},
},
}Step 3: 构造 Agent 类
我们在 src/core.py 文件中定义 Agent 类。这个类负责管理对话历史、调用 OpenAI API、处理工具调用请求以及执行工具函数。
# src/core.py (部分)
from openai import OpenAI
import json
from typing import List, Dict, Any
from utils import function_to_json
# 导入定义好的工具函数
from tools import get_current_datetime, add, compare, count_letter_in_string
SYSTEM_PROMPT = """
你是一个叫不要葱姜蒜的人工智能助手。你的输出应该与用户的语言保持一致。
当用户的问题需要调用工具时,你可以从提供的工具列表中调用适当的工具函数。
"""
class Agent:
def __init__(self, client: OpenAI, model: str = "Qwen/Qwen2.5-32B-Instruct", tools: List=[], verbose : bool = True):
self.client = client
self.tools = tools
self.model = model
self.messages = [
{"role": "system", "content": SYSREM_PROMPT},
]
self.verbose = verbose
def get_tool_schema(self) -> List[Dict[str, Any]]:
# 获取所有工具的 JSON 模式
return [function_to_json(tool) for tool in self.tools]
def handle_tool_call(self, tool_call):
# 处理工具调用
function_name = tool_call.function.name
function_args = tool_call.function.arguments
function_id = tool_call.id
function_call_content = eval(f"{function_name}(**{function_args})")
return {
"role": "tool",
"content": function_call_content,
"tool_call_id": function_id,
}
def get_completion(self, prompt) -> str:
self.messages.append({"role": "user", "content": prompt})
# 获取模型的完成响应
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.get_tool_schema(),
stream=False,
)
# 检查模型是否调用了工具
if response.choices[0].message.tool_calls:
self.messages.append({"role": "assistant", "content": response.choices[0].message.content})
# 处理工具调用
tool_list = []
for tool_call in response.choices[0].message.tool_calls:
# 处理工具调用并将结果添加到消息列表中
self.messages.append(self.handle_tool_call(tool_call))
tool_list.append([tool_call.function.name, tool_call.function.arguments])
if self.verbose:
print("调用工具:", response.choices[0].message.content, tool_list)
# 再次获取模型的完成响应,这次包含工具调用的结果
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.get_tool_schema(),
stream=False,
)
# 将模型的完成响应添加到消息列表中
self.messages.append({"role": "assistant", "content": response.choices[0].message.content})
return response.choices[0].message.contentAgent 的工作流程如下:
接收用户输入。
调用大模型(如 Qwen),并告知其可用的工具及其 Schema。
如果模型决定调用工具,Agent 会解析请求,执行相应的 Python 函数。
Agent 将工具的执行结果返回给模型。
模型根据工具结果生成最终回复。
Agent 将最终回复返回给用户。
如图7.9所示,Agent 调用工具流程:
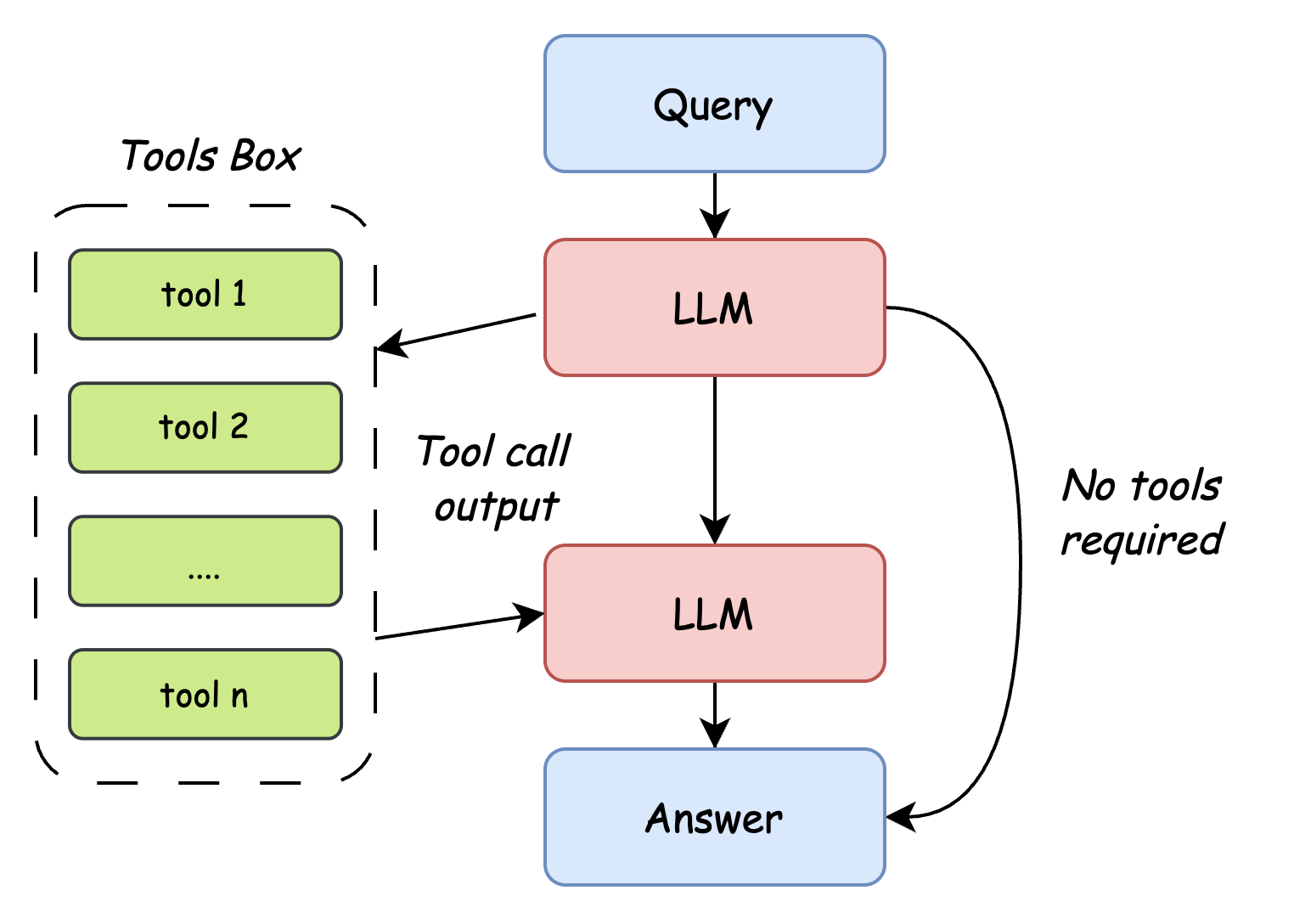
图7.9 Agent 工作流程
Step 4: 运行 Agent
现在我们可以实例化并运行 Agent。在 demo.py 的 if __name__ == "__main__": 部分提供了一个简单的命令行交互示例。
# demo.py (部分)
if __name__ == "__main__":
client = OpenAI(
api_key="YOUR_API_KEY", # 替换为你的 API Key
base_url="https://api.siliconflow.cn/v1",
)
# 创建 Agent 实例,传入 client、模型名称和工具函数列表
agent = Agent(
client=client,
model="Qwen/Qwen2.5-32B-Instruct",
tools=[get_current_datetime, add, compare, count_letter_in_string],
verbose=True # 设置为 True 可以看到工具调用信息
)
# 开始交互式对话循环
while True:
# 使用彩色输出区分用户输入和AI回答
prompt = input("\033[94mUser: \033[0m") # 蓝色显示用户输入提示
if prompt.lower() == "exit":
break
response = agent.get_completion(prompt)
print("\033[92mAssistant: \033[0m", response) # 绿色显示AI助手回答示例交互:
User: 你好
Assistant: 你好!有什么可以帮助你的吗?
User: 9.12和9 .2哪个更大?
调用工具: ['compare']
Assistant: 9.2 比 9.12 更大。
User: 为什么?
Assistant: 当我们比较9.12和9.2时,可以将它们看作是9.12和9.20。由于9.20在小数点后第二位是0,而9.12在小数点后第二位是2,所以在小数点后第一位相等的情况下,9.20(即9.2)大于9.12。因此,9.2 比 9.12 更大。
User: strawberry中有几个r?
调用工具: ['count_letter_in_string']
Assistant: 单词 "strawberry" 中有3个字母 'r'。
User: 你确信嘛?
调用工具: ['count_letter_in_string']
Assistant: 是的,我确定。单词 "strawberry" 中确实有3个字母 'r'。让我们再次确认一下,"strawberry" 中的 'r' 确实出现了3次。
User: 好的 你很薄,现在几点 了?
调用工具: ['get_current_datetime']
Assistant: 当前的时间是2025年4月26日17:01:33。不过,我注意到您提到“你很薄”,这似乎是一个打字错误,如果您有任何其他问题或者需要进一步的帮助,请告诉我!
User: exit另外,我们也准备了一份可以展示的 Streamlit 应用,可以运行在本地,展示 Agent 的功能。streamlit run web_demo.py 来运行,以下为 Agent 运行效果。

图 7.10 Streamlit Demo
参考文献
[1] Hugging Face. (2023). Open LLM Leaderboard: 开源大语言模型基准测试平台. https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
[2] awacke1. (2023). LMSYS Chatbot Arena Leaderboard: 大型语言模型竞技场评估平台. https://huggingface.co/spaces/awacke1/lmsys-chatbot-arena-leaderboard
[3] OpenCompass 团队. (2023). OpenCompass: 大模型统一评测平台. https://rank.opencompass.org.cn/home
[4] OpenCompass 金融榜团队. (2024). CFBENCHMARK: 金融领域大模型评测榜单. https://specialist.opencompass.org.cn/CFBenchmark
[5] OpenCompass 安全榜团队. (2024). Flames: 大模型安全评测榜单. https://flames.opencompass.org.cn/leaderboard
[6] OpenCompass 通识榜团队. (2024). BotChat: 大模型通用对话能力评测. https://botchat.opencompass.org.cn/
[7] OpenCompass 法律榜团队. (2024). LawBench: 法律领域大模型评测. https://lawbench.opencompass.org.cn/leaderboard
[8] OpenCompass 医疗榜团队. (2024). MedBench: 医疗领域大模型评测. https://medbench.opencompass.org.cn/leaderboard
[9] Zhi Jing, Yongye Su, and Yikun Han. (2024). When Large Language Models Meet Vector Databases: A Survey. arXiv preprint arXiv:2402.01763.
[10] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv preprint arXiv:2312.10997.
[11] Zhiruo Wang, Jun Araki, Zhengbao Jiang, Md Rizwan Parvez, 和 Graham Neubig. (2023). Learning to Filter Context for Retrieval-Augmented Generation. arXiv preprint arXiv:2311.08377.
[12] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown 和 Yoav Shoham. (2023). In-Context Retrieval-Augmented Language Models. arXiv preprint arXiv:2302.00083.
评论区