



3.1 Encoder-only PLM
在上一章,我们详细讲解了给 NLP 领域带来巨大变革注意力机制以及使用注意力机制搭建的模型 Transformer,NLP 模型的里程碑式转变也就自此而始。在上文对 Transformer 的讲解中我们可以看到,Transformer 结构主要由 Encoder、Decoder 两个部分组成,两个部分分别具有不一样的结构和输入输出。
针对 Encoder、Decoder 的特点,引入 ELMo 的预训练思路,开始出现不同的、对 Transformer 进行优化的思路。例如,Google 仅选择了 Encoder 层,通过将 Encoder 层进行堆叠,再提出不同的预训练任务-掩码语言模型(Masked Language Model,MLM),打造了一统自然语言理解(Natural Language Understanding,NLU)任务的代表模型——BERT。而 OpenAI 则选择了 Decoder 层,使用原有的语言模型(Language Model,LM)任务,通过不断增加模型参数和预训练语料,打造了在 NLG(Natural Language Generation,自然语言生成)任务上优势明显的 GPT 系列模型,也是现今大火的 LLM 的基座模型。当然,还有一种思路是同时保留 Encoder 与 Decoder,打造预训练的 Transformer 模型,例如由 Google 发布的 T5模型。
在本章中,我们将以 Encoder-Only、Encoder-Decoder、Decoder-Only 的顺序来依次介绍 Transformer 时代的各个主流预训练模型,分别介绍三种核心的模型架构、每种主流模型选择的预训练任务及其独特优势,这也是目前所有主流 LLM 的模型基础。
3.1.1 BERT
BERT,全名为 Bidirectional Encoder Representations from Transformers,是由 Google 团队在 2018年发布的预训练语言模型。该模型发布于论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,实现了包括 GLUE、MultiNLI 等七个自然语言处理评测任务的最优性能(State Of The Art,SOTA),堪称里程碑式的成果。自 BERT 推出以来,预训练+微调的模式开始成为自然语言处理任务的主流,不仅 BERT 自身在不断更新迭代提升模型性能,也出现了如 MacBERT、BART 等基于 BERT 进行优化提升的模型。可以说,BERT 是自然语言处理的一个阶段性成果,标志着各种自然语言处理任务的重大进展以及预训练模型的统治地位建立,一直到 LLM 的诞生,NLP 领域的主导地位才从 BERT 系模型进行迁移。即使在 LLM 时代,要深入理解 LLM 与 NLP,BERT 也是无法绕过的一环。
(1)思想沿承
BERT 是一个统一了多种思想的预训练模型。其所沿承的核心思想包括:
Transformer 架构。正如我们在上一章所介绍的,在 2017年发表的《Attention is All You Need》论文提出了完全使用 注意力机制而抛弃 RNN、LSTM 结构的 Transformer 模型,带来了新的模型架构。BERT 正沿承了 Transformer 的思想,在 Transformer 的模型基座上进行优化,通过将 Encoder 结构进行堆叠,扩大模型参数,打造了在 NLU 任务上独居天分的模型架构;
预训练+微调范式。同样在 2018年,ELMo 的诞生标志着预训练+微调范式的诞生。ELMo 模型基于双向 LSTM 架构,在训练数据上基于语言模型进行预训练,再针对下游任务进行微调,表现出了更加优越的性能,将 NLP 领域导向预训练+微调的研究思路。而 BERT 也采用了该范式,并通过将模型架构调整为 Transformer,引入更适合文本理解、能捕捉深层双向语义关系的预训练任务 MLM,将预训练-微调范式推向了高潮。
接下来,我们将从模型架构、预训练任务以及下游任务微调三个方面深入剖析 BERT,分析 BERT 的核心思路及优势,帮助大家理解 BERT 为何能够具备远超之前模型的性能,也从而更加深刻地理解 LLM 如何能够战胜 BERT 揭开新时代的大幕。
(2)模型架构——Encoder Only
BERT 的模型架构是取了 Transformer 的 Encoder 部分堆叠而成,其主要结构如图3.1所示:
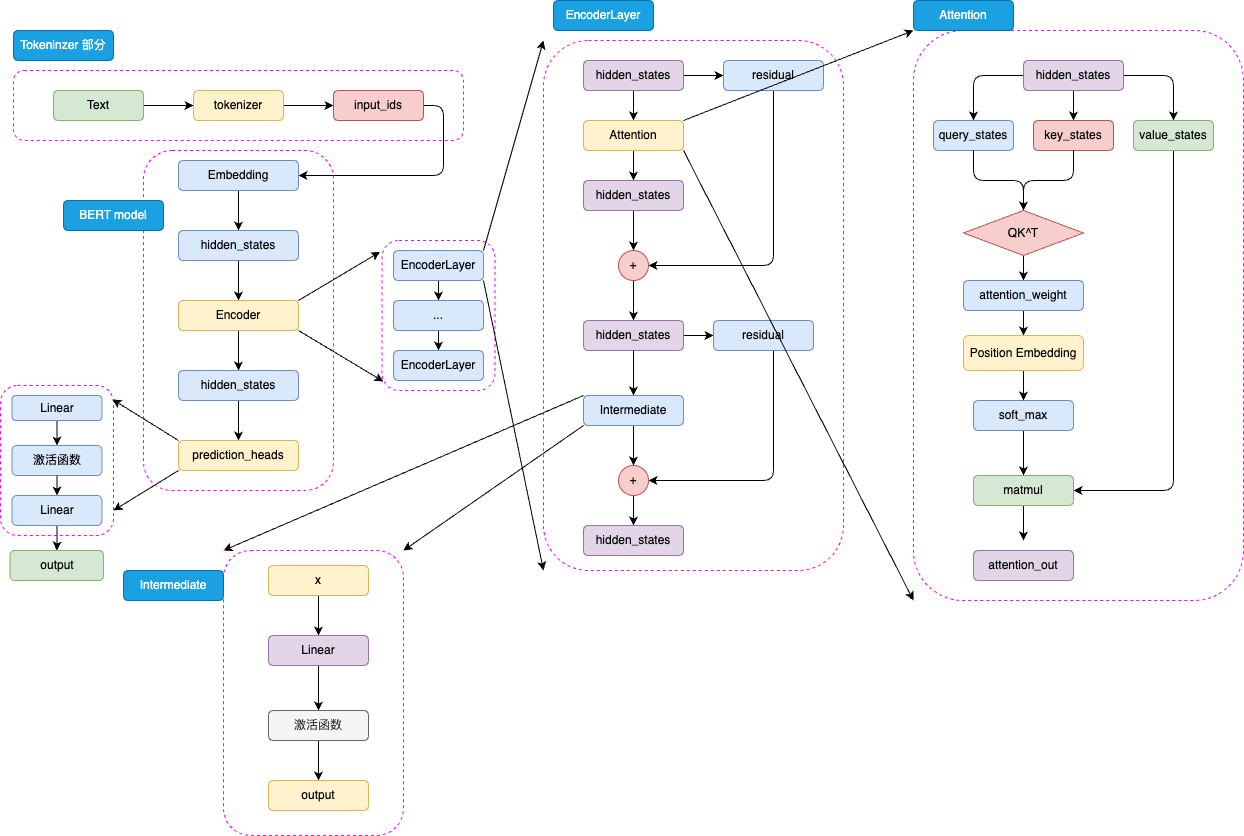
图3.1 BERT 模型结构
BERT 是针对于 NLU 任务打造的预训练模型,其输入一般是文本序列,而输出一般是 Label,例如情感分类的积极、消极 Label。但是,正如 Transformer 是一个 Seq2Seq 模型,使用 Encoder 堆叠而成的 BERT 本质上也是一个 Seq2Seq 模型,只是没有加入对特定任务的 Decoder,因此,为适配各种 NLU 任务,在模型的最顶层加入了一个分类头 prediction_heads,用于将多维度的隐藏状态通过线性层转换到分类维度(例如,如果一共有两个类别,prediction_heads 输出的就是两维向量)。
模型整体既是由 Embedding、Encoder 加上 prediction_heads 组成:
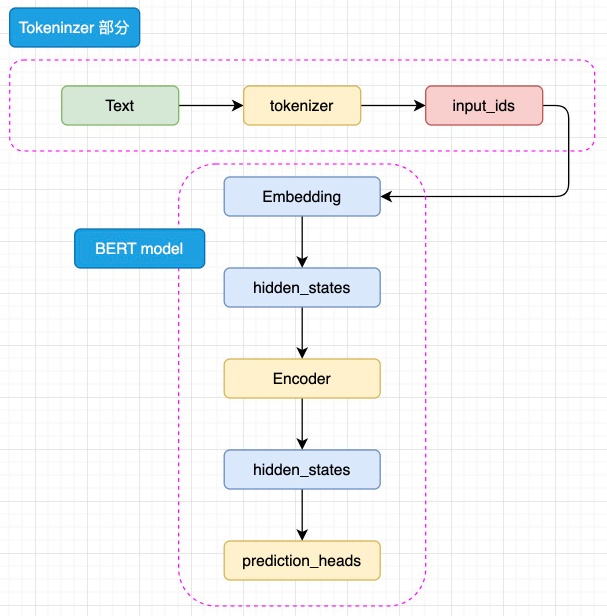
图3.2 BERT 模型简略结构
输入的文本序列会首先通过 tokenizer(分词器) 转化成 input_ids(基本每一个模型在 tokenizer 的操作都类似,可以参考 Transformer 的 tokenizer 机制,后文不再赘述),然后进入 Embedding 层转化为特定维度的 hidden_states,再经过 Encoder 块。Encoder 块中是对叠起来的 N 层 Encoder Layer,BERT 有两种规模的模型,分别是 base 版本(12层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。通过Encoder 编码之后的最顶层 hidden_states 最后经过 prediction_heads 就得到了最后的类别概率,经过 Softmax 计算就可以计算出模型预测的类别。
BERT 采用 WordPiece 作为分词方法。WordPiece 是一种基于统计的子词切分算法,其核心在于将单词拆解为子词(例如,"playing" -> ["play", "##ing"])。其合并操作的依据是最大化语言模型的似然度。对于中文等非空格分隔的语言,通常将单个汉字作为原子分词单位(token)处理。
prediction_heads 其实就是线性层加上激活函数,一般而言,最后一个线性层的输出维度和任务的类别数相等,如图3.3所示:
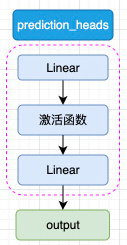
图3.3 prediction_heads 结构
而每一层 Encoder Layer 都是和 Transformer 中的 Encoder Layer 结构类似的层,如图3.4所示:
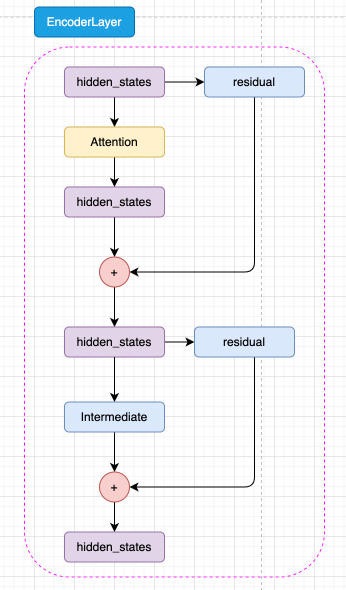
图3.4 Encoder Layer 结构
如图3.5所示,已经通过 Embedding 层映射的 hidden_states 进入核心的 attention 机制,然后通过残差连接的机制和原输入相加,再经过一层 Intermediate 层得到最终输出。Intermediate 层是 BERT 的特殊称呼,其实就是一个线性层加上激活函数:
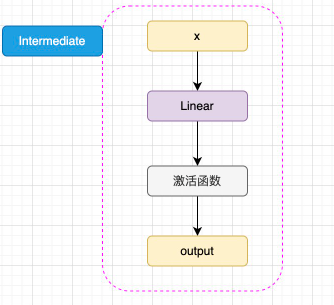
图3.5 Intermediate 结构
注意,BERT 所使用的激活函数是 GELU 函数,全名为高斯误差线性单元激活函数,这也是自 BERT 才开始被普遍关注的激活函数。GELU 的计算方式为:
GELU(x)=0.5x(1+tanh(2π)(x+0.044715x3))
GELU 的核心思路为将随机正则的思想引入激活函数,通过输入自身的概率分布,来决定抛弃还是保留自身的神经元。关于 GELU 的原理与核心思路,此处不再赘述,有兴趣的读者可以自行学习。
BERT 的 注意力机制和 Transformer 中 Encoder 的 自注意力机制几乎完全一致,但是 BERT 将相对位置编码融合在了注意力机制中,将相对位置编码同样视为可训练的权重参数,如图3.6所示:
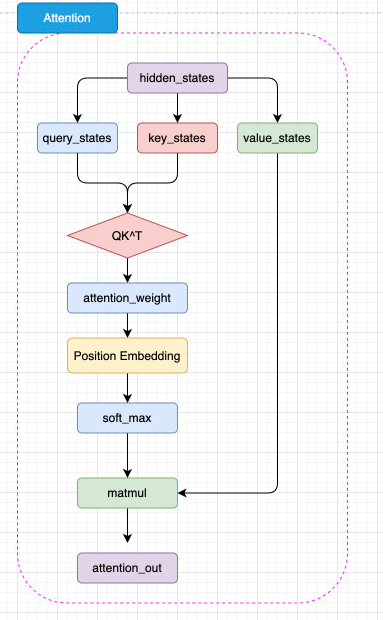
图3.6 BERT 注意力机制结构
如图,BERT 的注意力计算过程和 Transformer 的唯一差异在于,在完成注意力分数的计算之后,先通过 Position Embedding 层来融入相对位置信息。这里的 Position Embedding 层,其实就是一层线性矩阵。通过可训练的参数来拟合相对位置,相对而言比 Transformer 使用的绝对位置编码 Sinusoidal 能够拟合更丰富的相对位置信息,但是,这样也增加了不少模型参数,同时完全无法处理超过模型训练长度的输入(例如,对 BERT 而言能处理的最大上下文长度是 512 个 token)。
可以看出,BERT 的模型架构既是建立在 Transformer 的 Encoder 之上的,这也是为什么说 BERT 沿承了 Transformer 的思想。
(3)预训练任务——MLM + NSP
相较于基本沿承 Transformer 的模型架构,BERT 更大的创新点在于其提出的两个新的预训练任务上——MLM 和 NSP(Next Sentence Prediction,下一句预测)。预训练-微调范式的核心优势在于,通过将预训练和微调分离,完成一次预训练的模型可以仅通过微调应用在几乎所有下游任务上,只要微调的成本较低,即使预训练成本是之前的数倍甚至数十倍,模型仍然有更大的应用价值。因此,可以进一步扩大模型参数和预训练数据量,使用海量的预训练语料来让模型拟合潜在语义与底层知识,从而让模型通过长时间、大规模的预训练获得强大的语言理解和生成能力。
因此,预训练数据的核心要求即是需要极大的数据规模(数亿 token)。毫无疑问,通过人工标注产出的全监督数据很难达到这个规模。因此,预训练数据一定是从无监督的语料中获取。这也是为什么传统的预训练任务都是 LM 的原因——LM 使用上文预测下文的方式可以直接应用到任何文本中,对于任意文本,我们只需要将下文遮蔽将上文输入模型要求其预测就可以实现 LM 训练,因此互联网上所有文本语料都可以被用于预训练。
但是,LM 预训练任务的一大缺陷在于,其直接拟合从左到右的语义关系,但忽略了双向的语义关系。虽然 Transformer 中通过位置编码表征了文本序列中的位置信息,但这和直接拟合双向语义关系还是有本质区别。例如,BiLSTM(双向 LSTM 模型)在语义表征上就往往优于 LSTM 模型,就是因为 BiLSTM 通过双向的 LSTM 拟合了双向语义关系。因此,有没有一种预训练任务,能够既利用海量无监督语料,又能够训练模型拟合双向语义关系的能力?
基于这一思想,Jacob 等学者提出了 MLM,也就是掩码语言模型作为新的预训练任务。相较于模拟人类写作的 LM,MLM 模拟的是“完形填空”。MLM 的思路也很简单,在一个文本序列中随机遮蔽部分 token,然后将所有未被遮蔽的 token 输入模型,要求模型根据输入预测被遮蔽的 token。例如,输入和输出可以是:
输入:I <MASK> you because you are <MASK>
输出:<MASK> - love; <MASK> - wonderful
由于模型可以利用被遮蔽的 token 的上文和下文一起理解语义来预测被遮蔽的 token,因此通过这样的任务,模型可以拟合双向语义,也就能够更好地实现文本的理解。同样,MLM 任务无需对文本进行任何人为的标注,只需要对文本进行随机遮蔽即可,因此也可以利用互联网所有文本语料实现预训练。例如,BERT 的预训练就使用了足足 3300M 单词的语料。
不过,MLM 也存在其固有缺陷。LM 任务模拟了人自然创作的过程,其训练和下游任务是完全一致的,也就是说,训练时是根据上文预测下文,下游任务微调和推理时也同样如此。但是 MLM 不同,在下游任务微调和推理时,其实是不存在我们人工加入的 <MASK> 的,我们会直接通过原文本得到对应的隐藏状态再根据下游任务进入分类器或其他组件。预训练和微调的不一致,会极大程度影响模型在下游任务微调的性能。针对这一问题,作者对 MLM 的策略进行了改进。
在具体进行 MLM 训练时,会随机选择训练语料中 15% 的 token 用于遮蔽。但是这 15% 的 token 并非全部被遮蔽为 <MASK>,而是有 80% 的概率被遮蔽,10% 的概率被替换为任意一个 token,还有 10% 的概率保持不变。其中 10% 保持不变就是为了消除预训练和微调的不一致,而 10% 的随机替换核心意义在于迫使模型保持对上下文信息的学习。因为如果全部遮蔽的话,模型仅需要处理被遮蔽的位置,从而仅学习要预测的 token 而丢失了对上下文的学习。通过引入部分随机 token,模型无法确定需要预测的 token,从而被迫保持每一个 token 的上下文表征分布,从而具备了对句子的特征表示能力。且由于随机 token 的概率很低,其并不会影响模型实质的语言理解能力。
除去 MLM,BERT 还提出了另外一个预训练任务——NSP,即下一个句子预测。NSP 的核心思想是针对句级的 NLU 任务,例如问答匹配、自然语言推理等。问答匹配是指,输入一个问题和若干个回答,要求模型找出问题的真正回答;自然语言推理是指,输入一个前提和一个推理,判断推理是否是符合前提的。这样的任务都需要模型在句级去拟合关系,判断两个句子之间的关系,而不仅是 MLM 在 token 级拟合的语义关系。因此,BERT 提出了 NSP 任务来训练模型在句级的语义关系拟合。
NSP 任务的核心思路是要求模型判断一个句对的两个句子是否是连续的上下文。例如,输入和输入可以是:
输入:
Sentence A:I love you.
Sentence B: Because you are wonderful.
输出:
1(是连续上下文)
输入:
Sentence A:I love you.
Sentence B: Because today's dinner is so nice.
输出:
0(不是连续上下文)
通过要求模型判断句对关系,从而迫使模型拟合句子之间的关系,来适配句级的 NLU 任务。同样,由于 NSP 的正样本可以从无监督语料中随机抽取任意连续的句子,而负样本可以对句子打乱后随机抽取(只需要保证不要抽取到原本就连续的句子就行),因此也可以具有几乎无限量的训练数据。
在具体预训练时,BERT 使用了 800M 的 BooksCorpus 语料和 2500M 的英文维基百科语料,90% 的数据使用 128 的上下文长度训练,剩余 10% 的数据使用 512 作为上下文长度进行预训练,总共约训练了 3.3B token。其训练的超参数也是值得关注的,BERT 的训练语料共有 13GB 大小,其在 256 的 batch size 上训练了 1M 步(40 个 Epoch)。而相较而言,LLM 一般都只会训练一个 Epoch,且使用远大于 256 的 batch size。
可以看到,相比于传统的非预训练模型,其训练的数据量有指数级增长。当然,更海量的训练数据需要更大成本的算力,BERT 的 Base 版本和 Large 版本分别使用了 16块 TPU 和 64块 TPU 训练了 4天才完成。
(4)下游任务微调
作为 NLP 领域里程碑式的成果,BERT 的一个重大意义就是正式确立了预训练-微调的两阶段思想,即在海量无监督语料上进行预训练来获得通用的文本理解与生成能力,再在对应的下游任务上进行微调。该种思想的一个重点在于,预训练得到的强大能力能否通过低成本的微调快速迁移到对应的下游任务上。
针对这一点,BERT 设计了更通用的输入和输出层来适配多任务下的迁移学习。对每一个输入的文本序列,BERT 会在其首部加入一个特殊 token <CLS>。在后续编码中,该 token 代表的即是整句的状态,也就是句级的语义表征。在进行 NSP 预训练时,就使用了该 token 对应的特征向量来作为最后分类器的输入。
在完成预训练后,针对每一个下游任务,只需要使用一定量的全监督人工标注数据,对预训练的 BERT 在该任务上进行微调即可。所谓微调,其实和训练时更新模型参数的策略一致,只不过在特定的任务、更少的训练数据、更小的 batch_size 上进行训练,更新参数的幅度更小。对于绝大部分下游任务,都可以直接使用 BERT 的输出。例如,对于文本分类任务,可以直接修改模型结构中的 prediction_heads 最后的分类头即可。对于序列标注等任务,可以集成 BERT 多层的隐含层向量再输出最后的标注结果。对于文本生成任务,也同样可以取 Encoder 的输出直接解码得到最终生成结果。因此,BERT 可以非常高效地应用于多种 NLP 任务。
BERT 一经提出,直接在 NLP 11个赛道上取得 SOTA 效果,成为 NLU 方向上当之无愧的霸主,后续若干在 NLU 任务上取得更好效果的模型都是在 BERT 基础上改进得到的。直至 LLM 时代,BERT 也仍然能在很多标注数据丰富的 NLU 任务上达到最优效果,事实上,对于某些特定、训练数据丰富且强调高吞吐的任务,BERT 比 LLM 更具有可用性。
3.1.2 RoBERTa
BERT 作为 NLP 划时代的杰作,同时在多个榜单上取得 SOTA 效果,也带动整个 NLP 领域向预训练模型方向迁移。以 BERT 为基础,在多个方向上进行优化,还涌现了一大批效果优异的 Encoder-Only 预训练模型。它们大都有和 BERT 类似或完全一致的模型结构,在训练数据、预训练任务、训练参数等方面上进行了优化,以取得能力更强大、在下游任务上表现更亮眼的预训练模型。其中之一即是同样由 Facebook 发布的 RoBERTa。
前面我们说过,预训练-微调的一个核心优势在于可以使用远大于之前训练数据的海量无监督语料进行预训练。因为在传统的深度学习范式中,对每一个任务,我们需要从零训练一个模型,那么就无法使用太大的模型参数,否则需要极大规模的有监督数据才能让模型较好地拟合,成本太大。但在预训练-微调范式,我们在预训练阶段可以使用尽可能大量的训练数据,只需要一次预训练好的模型,后续在每一个下游任务上通过少量有监督数据微调即可。而 BERT 就使用了 13GB(3.3B token)的数据进行预训练,这相较于传统 NLP 来说是一个极其巨大的数据规模了。
但是,13GB 的预训练数据是否让 BERT 达到了充分的拟合呢?如果我们使用更多预训练语料,是否可以进一步增强模型性能?更多的,BERT 所选用的预训练任务、训练超参数是否是最优的?RoBERTa 应运而生。
(1)优化一:去掉 NSP 预训练任务
RoBERTa 的模型架构与 BERT 完全一致,也就是使用了 BERT-large(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)的模型参数。在预训练任务上,有学者质疑 NSP 任务并不能提高模型性能,因为其太过简单,加入到预训练中并不能使下游任务微调时明显受益,甚至会带来负面效果。RoBERTa 设置了四个实验组:
1. 段落构建的 MLM + NSP:BERT 原始预训练任务,输入是一对片段,每个片段包括多个句子,来构造 NSP 任务;
2. 文档对构建的 MLM + NSP:一个输入构建一对句子,通过增大 batch 来和原始输入达到 token 等同;
3. 跨越文档的 MLM:去掉 NSP 任务,一个输入为从一个或多个文档中连续采样的完整句子,为使输入达到最大长度(512),可能一个输入会包括多个文档;
4. 单文档的 MLM:去掉 NSP 任务,且限制一个输入只能从一个文档中采样,同样通过增大 batch 来和原始输入达到 token 等同
实验结果证明,后两组显著优于前两组,且单文档的 MLM 组在下游任务上微调时性能最佳。因此,RoBERTa 在预训练中去掉了 NSP,只使用 MLM 任务。
同时,RoBERTa 对 MLM 任务本身也做出了改进。在 BERT 中,Mask 的操作是在数据处理的阶段完成的,因此后期预训练时同一个 sample 待预测的 <MASK> 总是一致的。由于 BERT 共训练了 40 个 Epoch,为使模型的训练数据更加广泛,BERT 将数据进行了四次随机 Mask,也就是每 10个 Epoch 模型训练的数据是完全一致的。而 RoBERTa 将 Mask 操作放到了训练阶段,也就是动态遮蔽策略,从而让每一个 Epoch 的训练数据 Mask 的位置都不一致。在实验中,动态遮蔽仅有很微弱的优势优于静态遮蔽,但由于动态遮蔽更高效、易于实现,后续 MLM 任务基本都使用了动态遮蔽。
(2)优化二:更大规模的预训练数据和预训练步长
RoBERTa 使用了更大量的无监督语料进行预训练,除去 BERT 所使用的 BookCorpus 和英文维基百科外,还使用了 CC-NEWS(CommonCrawl 数据集新闻领域的英文部分)、OPENWEBTEXT(英文网页)、STORIES(CommonCrawl 数据集故事风格子集),共计 160GB 的数据,十倍于 BERT。
同时,RoBERTa 认为更大的 batch size 既可以提高优化速度,也可以提高任务结束性能。因此,实验在 8K 的 batch size(对比 BERT 的 batch size 为 256)下训练 31K Step,也就是总训练 token 数和 BERT 一样是 3.3B 时,模型性能更好,从而证明了大 batch size 的意义。在此基础上,RoBERTa 一共训练了 500K Step(约合 66个 Epoch)。同时,RoBERTa 不再采用 BERT 在 256 长度上进行大部分训练再在 512 长度上完成训练的策略,而是全部在 512 长度上进行训练。
当然,更大的预训练数据、更长的序列长度和更多的训练 Epoch,需要预训练阶段更多的算力资源。训练一个 RoBERTa,Meta 使用了 1024 块 V100(32GB 显存)训练了一天。
(3)优化三:更大的 bpe 词表
与 BERT 使用的 WordPiece 算法不同,RoBERTa 使用了 BPE 作为 Tokenizer 的编码策略。BPE,即 Byte Pair Encoding,字节对编码,是指以子词对作为分词的单位。例如,对“Hello World”这句话,可能会切分为“Hel,lo,Wor,ld”四个子词对。而对于以字为基本单位的中文,一般会按照字节编码进行切分。例如,在 UTF-8 编码中,“我”会被编码为“E68891”,那么在 BPE 中可能就会切分成“E68”,“891”两个字词对。
一般来说,BPE 编码的词典越大,编码效果越好。当然,由于 Embedding 层就是把 token 从词典空间映射到隐藏空间(也就是说 Embedding 的形状为 (vocab_size, hidden_size),越大的词表也会带来模型参数的增加。
BERT 原始的 BPE 词表大小为 30K,RoBERTa 选择了 50K 大小的词表来优化模型的编码能力。
通过上述三个部分的优化,RoBERTa 成功地在 BERT 架构的基础上刷新了多个下游任务的 SOTA,也一度成为 BERT 系模型最热门的预训练模型。同时,RoBERTa 的成功也证明了更大的预训练数据、更大的预训练步长的重要意义,这也是 LLM 诞生的基础之一。
3.1.3 ALBERT
在 BERT 的基础上,RoBERTa 进一步探究了更大规模预训练的作用。同样是基于 BERT 架构进行优化的 ALBERT 模型,则从是否能够减小模型参数保持模型能力的角度展开了探究。通过对模型结构进行优化并对 NSP 预训练任务进行改进,ALBERT 成功地以更小规模的参数实现了超越 BERT 的能力。虽然 ALBERT 所提出的一些改进思想并没有在后续研究中被广泛采用,但其降低模型参数的方法及提出的新预训练任务 SOP 仍然对 NLP 领域提供了重要的参考意义。
(1)优化一:将 Embedding 参数进行分解
BERT 等预训练模型具有远超传统神经网络的参数量,如前所述,BERT-large 具有 24层 Encoder Layer,1024 的隐藏层维度,总共参数量达 340M。而这其中,Embedding 层的参数矩阵维度为 V∗H,此处的 V 为词表大小 30K,H 即为隐藏层大小 1024,也就是 Embedding 层参数达到了 30M。而这样的设置还会带来一个更大的问题,即 Google 探索尝试搭建更宽(也就是隐藏层维度更大)的模型时发现,隐藏层维度的增加会带来 Embedding 层参数的巨大上升,如果把隐藏层维度增加到 2048,Embedding 层参数就会膨胀到 61M,这无疑是极大增加了模型的计算开销。
而从另一个角度看,Embedding 层输出的向量是我们对文本 token 的稠密向量表示,从 Word2Vec 的成功经验来看,这种词向量并不需要很大的维度,Word2Vec 仅使用了 100维大小就取得了很好的效果。因此,Embedding 层的输出也许不需要和隐藏层大小一致。
因此,ALBERT 对 Embedding 层的参数矩阵进行了分解,让 Embedding 层的输出维度和隐藏层维度解绑,也就是在 Embedding 层的后面加入一个线性矩阵进行维度变换。ALBERT 设置了 Embedding 层的输出为 128,因此在 Embedding 层后面加入了一个 $1281024$ 的线性矩阵来将 Embedding 层的输出再升维到隐藏层大小。也就是说,Embedding 层的参数从 $VH$ 降低到了 $VE + EH$,当 E 的大小远小于 H 时,该方法对 Embedding 层参数的优化就会很明显。
(2)优化二:跨层进行参数共享
通过对 BERT 的参数进行分析,ALBERT 发现各个 Encoder 层的参数出现高度一致的情况。由于 24个 Encoder 层带来了巨大的模型参数,因此,ALBERT 提出,可以让各个 Encoder 层共享模型参数,来减少模型的参数量。
在具体实现上,其实就是 ALBERT 仅初始化了一个 Encoder 层。在计算过程中,仍然会进行 24次计算,但是每一次计算都是经过这一个 Encoder 层。因此,虽然是 24个 Encoder 计算的模型,但只有一层 Encoder 参数,从而大大降低了模型参数量。在这样的情况下,就可以极大程度地扩大隐藏层维度,实现一个更宽但参数量更小的模型。ALBERT 通过实验证明,相较于 334M 的 BERT,同样是 24层 Encoder 但将隐藏层维度设为 2048 的 ALBERT(xlarge 版本)仅有 59M 的参数量,但在具体效果上还要更优于 BERT。
但是,上述优化虽然极大程度减小了模型参数量并且还提高了模型效果,却也存在着明显的不足。虽然 ALBERT 的参数量远小于 BERT,但训练效率却只略微优于 BERT,因为在模型的设置中,虽然各层共享权重,但计算时仍然要通过 24次 Encoder Layer 的计算,也就是说训练和推理时的速度相较 BERT 还会更慢。这也是 ALBERT 最终没能取代 BERT 的一个重要原因。
(3)优化三:提出 SOP 预训练任务
类似于 RoBERTa,ALBERT 也同样认为 NSP 任务过于简单,在预训练中无法对模型效果的提升带来显著影响。但是不同于 RoBERTa 选择直接去掉 NSP,ALBERT 选择改进 NSP,增加其难度,来优化模型的预训练。
在传统的 NSP 任务中,正例是由两个连续句子组成的句对,而负例则是从任意两篇文档中抽取出的句对,模型可以较容易地判断正负例,并不能很好地学习深度语义。而 SOP 任务提出的改进是,正例同样由两个连续句子组成,但负例是将这两个的顺序反过来。也就是说,模型不仅要拟合两个句子之间的关系,更要学习其顺序关系,这样就大大提升了预训练的难度。例如,相较于我们在上文中提出的 NSP 任务的示例,SOP 任务的示例形如:
输入:
Sentence A:I love you.
Sentence B: Because you are wonderful.
输出:
1(正样本)
输入:
Sentence A:Because you are wonderful.
Sentence B: I love you.
输出:
0(负样本)
ALBERT 通过实验证明,SOP 预训练任务对模型效果有显著提升。使用 MLM + SOP 预训练的模型效果优于仅使用 MLM 预训练的模型更优于使用 MLM + NSP 预训练的模型。
通过上述三点优化,ALBERT 成功地以更小的参数实现了更强的性能,虽然由于其架构带来的训练、推理效率降低限制了模型的进一步发展,但打造更宽的模型这一思路仍然为众多更强大的模型提供了参考价值。
作为预训练时代的 NLP 王者,BERT 及 BERT 系模型在多个 NLP 任务上扮演了极其重要的角色。除去上文介绍过的 RoBERTa、ALBERT 外,还有许多从其他更高角度对 BERT 进行优化的后起之秀,包括进一步改进了预训练任务的 ERNIE、对 BERT 进行蒸馏的小模型 DistilBERT、主打多语言任务的 XLM 等,本文就不再一一赘述。以 BERT 为代表的 Encoder-Only 架构并非 Transformer 的唯一变种,接下来,我们将介绍 Transformer 的另一种主流架构,与原始 Transformer 更相似、以 T5 为代表的 Encoder-Decoder 架构。
3.2 Encoder-Decoder PLM
在上一节,我们学习了 Encoder-Only 结构的模型,主要介绍了 BERT 的模型架构、预训练任务和下游任务微调。BERT 是一个基于 Transformer 的 Encoder-Only 模型,通过预训练任务 MLM 和 NSP 来学习文本的双向语义关系,从而在下游任务中取得了优异的性能。但是,BERT 也存在一些问题,例如 MLM 任务和下游任务微调的不一致性,以及无法处理超过模型训练长度的输入等问题。为了解决这些问题,研究者们提出了 Encoder-Decoder 模型,通过引入 Decoder 部分来解决这些问题,同时也为 NLP 领域带来了新的思路和方法。
在本节中,我们将学习 Encoder-Decoder 结构的模型,主要介绍 T5 的模型架构和预训练任务,以及 T5 模型首次提出的 NLP 大一统思想。
3.2.1 T5
T5(Text-To-Text Transfer Transformer)是由 Google 提出的一种预训练语言模型,通过将所有 NLP 任务统一表示为文本到文本的转换问题,大大简化了模型设计和任务处理。T5 基于 Transformer 架构,包含编码器和解码器两个部分,使用自注意力机制和多头注意力捕捉全局依赖关系,利用相对位置编码处理长序列中的位置信息,并在每层中包含前馈神经网络进一步处理特征。
T5 的大一统思想将不同的 NLP 任务如文本分类、问答、翻译等统一表示为输入文本到输出文本的转换,这种方法简化了模型设计、参数共享和训练过程,提高了模型的泛化能力和效率。通过这种统一处理方式,T5不仅减少了任务特定的模型调试工作,还能够使用相同的数据处理和训练框架,极大地提升了多任务学习的性能和应用的便捷性。接下来我们将会从模型结构、预训练任务和大一统思想三个方面来介绍 T5 模型。
(1)模型结构:Encoder-Decoder
BERT 采用了 Encoder-Only 结构,只包含编码器部分;而 GPT 采用了 Decoder-Only 结构,只包含解码器部分。T5 则采用了 Encoder-Decoder 结构,其中编码器和解码器都是基于 Transformer 架构设计。编码器用于处理输入文本,解码器用于生成输出文本。编码器和解码器之间通过注意力机制进行信息交互,从而实现输入文本到输出文本的转换。其主要结构如图3.7所示:
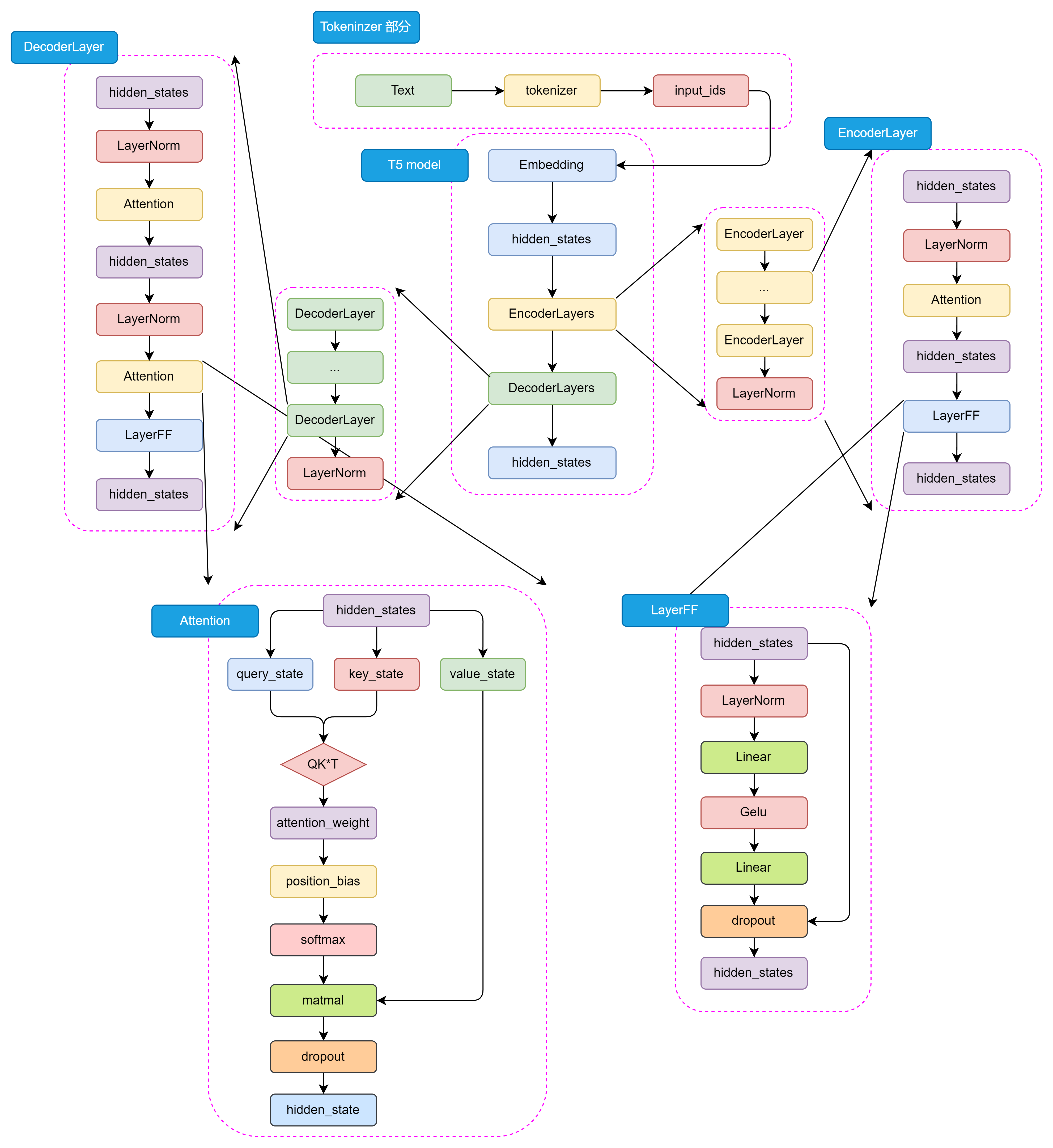
图3.7 T5 模型详细结构
如图3.8所示,从整体来看 T5 的模型结构包括 Tokenizer 部分和 Transformer 部分。Tokenizer 部分主要负责将输入文本转换为模型可接受的输入格式,包括分词、编码等操作。Transformer 部分又分为 EncoderLayers 和 DecoderLayers 两部分,他们分别由一个个小的 Block组成,每个 Block 包含了多头注意力机制、前馈神经网络和 Norm 层。Block 的设计可以使模型更加灵活,像乐高一样可以根据任务的复杂程度和数据集的大小来调整 Block 的数量和层数。
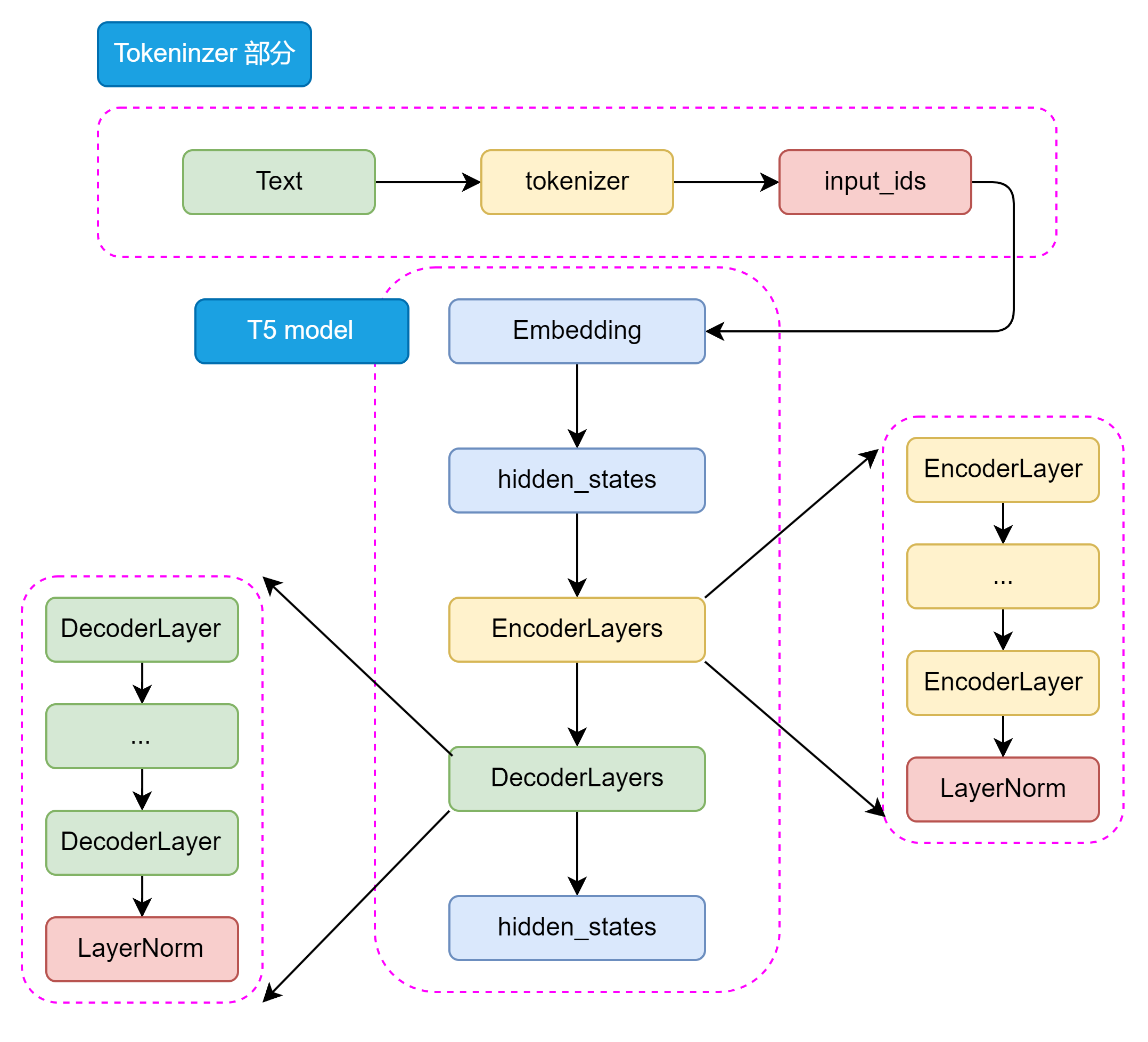
图3.8 T5 模型整体结构
T5 模型的 Encoder 和 Decoder 部分都是基于 Transformer 架构设计的,主要包括 Self-Attention 和前馈神经网络两种结构。Self-Attention 用于捕捉输入序列中的全局依赖关系,前馈神经网络用于处理特征的非线性变换。
和 Encoder 不一样的是,在 Decoder 中还包含了 Encoder-Decoder Attention 结构,用于捕捉输入和输出序列之间的依赖关系。这两种 Attention 结构几乎完全一致,只有在位置编码和 Mask 机制上有所不同。如图3.9所示,Encoder 和 Decoder 的结构如下:
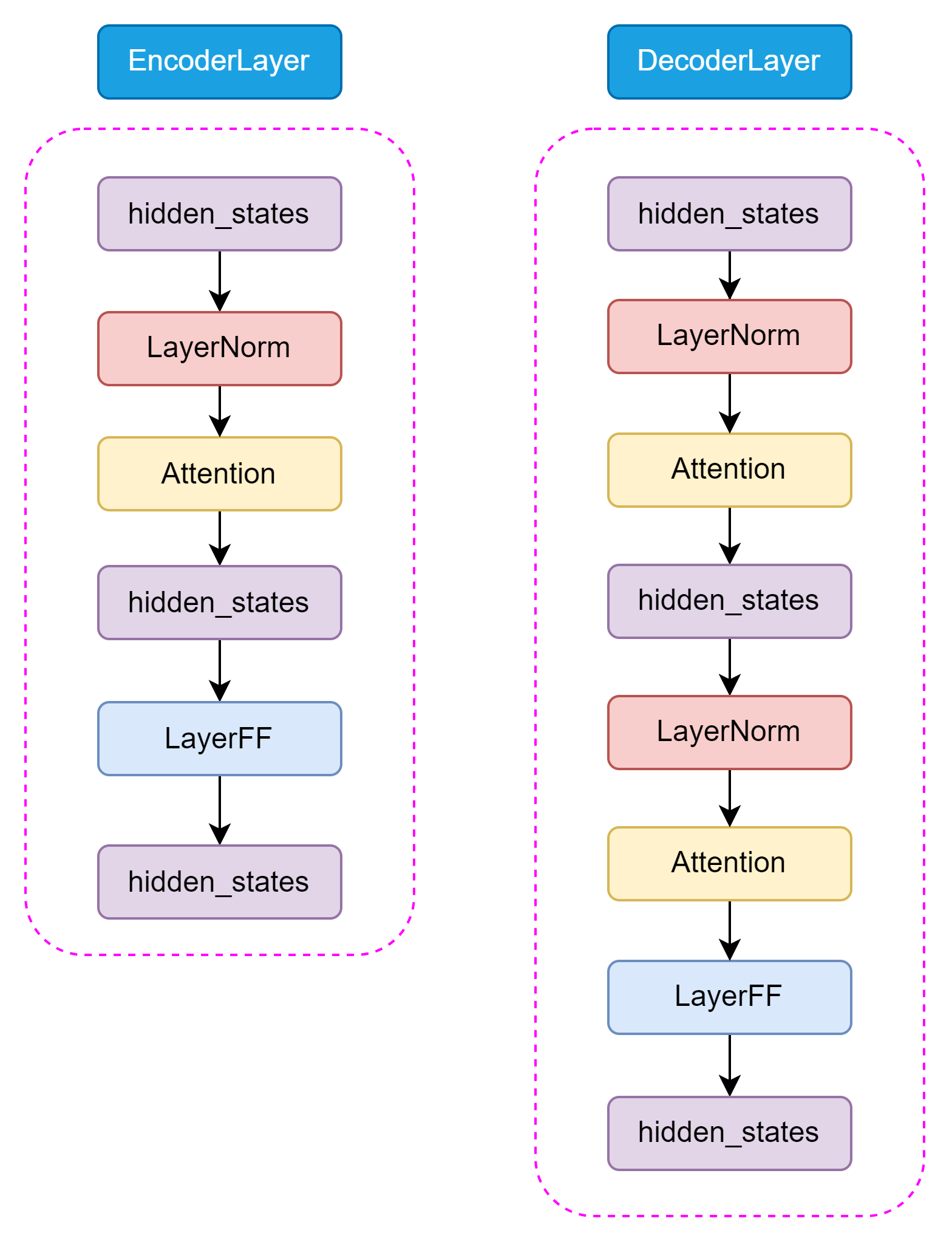
图3.9 Encoder 和 Decoder
T5 的 Self-Attention 机制和 BERT 的 Attention 机制是一样的,都是基于 Self-Attention 机制设计的。Self-Attention 机制是一种全局依赖关系建模方法,通过计算 Query、Key 和 Value 之间的相似度来捕捉输入序列中的全局依赖关系。Encoder-Decoder Attention 仅仅在位置编码和 Mask 机制上有所不同,主要是为了区分输入和输出序列。如图3.10所示,Self-Attention 结构如下:
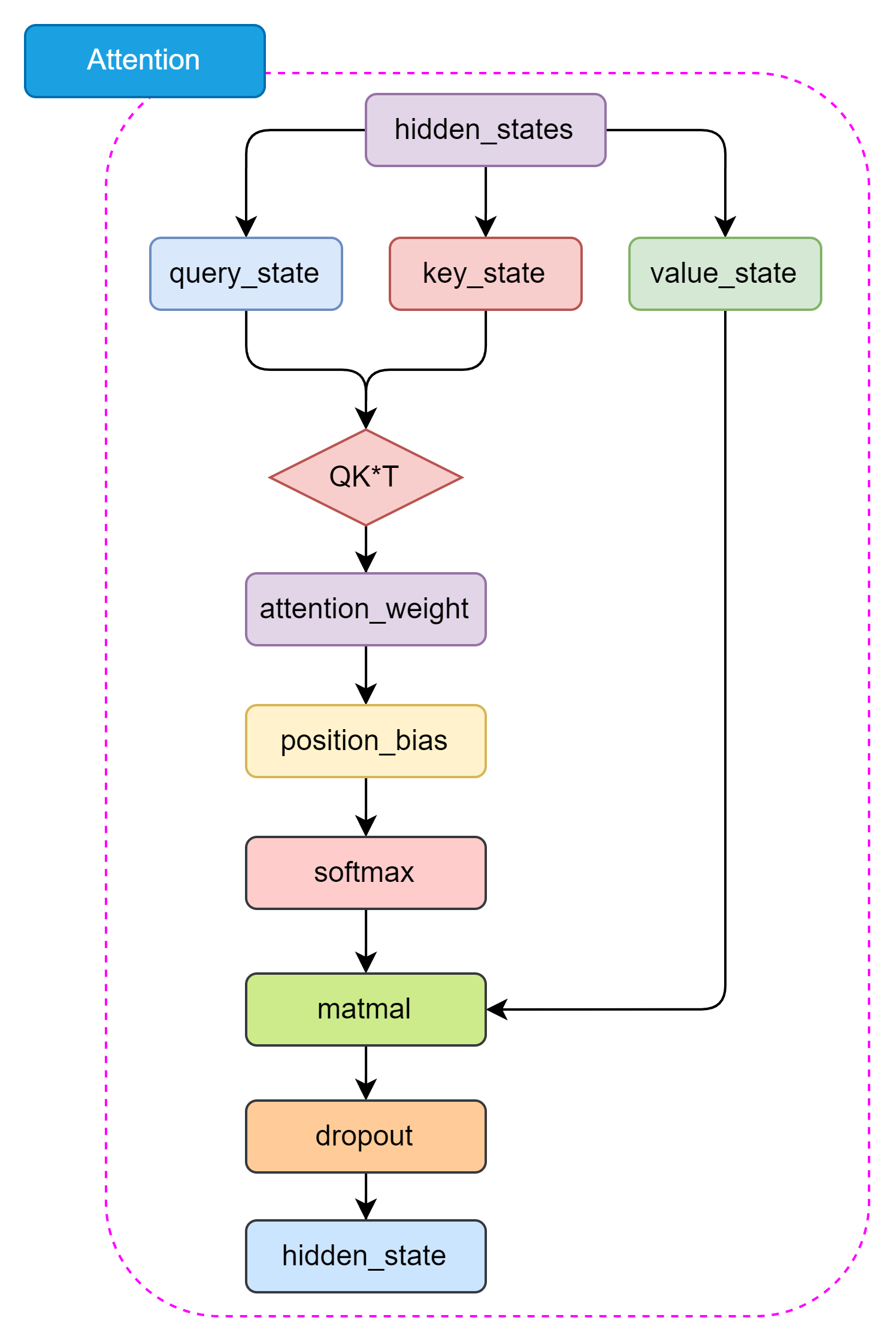
图3.10 Self-Attention 结构
与原始 Transformer 模型不同,T5 模型的LayerNorm 采用了 RMSNorm,通过计算每个神经元的均方根(Root Mean Square)来归一化每个隐藏层的激活值。RMSNorm 的参数设置与Layer Normalization 相比更简单,只有一个可学参数,可以更好地适应不同的任务和数据集。RMSNorm函数可以用以下数学公式表示:
RMSNorm(x)=x1n∑i=1nxi2+ϵ⋅γ
其中:
xi 是输入向量的第 i 个元素
γ 是可学习的缩放参数
n 是输入向量的维度数量
ϵ 是一个小常数,用于数值稳定性(以避免除以零的情况)
这种归一化有助于通过确保权重的规模不会变得过大或过小来稳定学习过程,这在具有许多层的深度学习模型中特别有用。
(2)预训练任务
T5 模型的预训练任务是一个关键的组成部分,它能使模型能够学习到丰富的语言表示,语言表示能力可以在后续的微调过程中被迁移到各种下游任务。训练所使用的数据集是一个大规模的文本数据集,包含了各种各样的文本数据,如维基百科、新闻、书籍等等。对数据经过细致的处理后,生成了用于训练的750GB 的数据集 C4,且已在 TensorflowData 中开源。
我们可以简单概括一下 T5 的预训练任务,主要包括以下几个部分:
预训练任务: T5模型的预训练任务是 MLM,也称为BERT-style目标。具体来说,就是在输入文本中随机遮蔽15%的token,然后让模型预测这些被遮蔽的token。这个过程不需要标签,可以在大量未标注的文本上进行。
输入格式: 预训练时,T5将输入文本转换为"文本到文本"的格式。对于一个给定的文本序列,随机选择一些token进行遮蔽,并用特殊的占位符(token)替换。然后将被遮蔽的token序列作为模型的输出目标。
预训练数据集: T5 使用了自己创建的大规模数据集"Colossal Clean Crawled Corpus"(C4),该数据集从Common Crawl中提取了大量干净的英语文本。C4数据集经过了一定的清洗,去除了无意义的文本、重复文本等。
多任务预训练: T5 还尝试了将多个任务混合在一起进行预训练,而不仅仅是单独的MLM任务。这有助于模型学习更通用的语言表示。
预训练到微调的转换: 预训练完成后,T5模型会在下游任务上进行微调。微调时,模型在任务特定的数据集上进行训练,并根据任务调整解码策略。
通过大规模预训练,T5模型能够学习到丰富的语言知识,并获得强大的语言表示能力,在多个NLP任务上取得了优异的性能,预训练是T5成功的关键因素之一。
(3)大一统思想
T5模型的一个核心理念是“大一统思想”,即所有的 NLP 任务都可以统一为文本到文本的任务,这一思想在自然语言处理领域具有深远的影响。其设计理念是将所有不同类型的NLP任务(如文本分类、翻译、文本生成、问答等)转换为一个统一的格式:输入和输出都是纯文本。
例如:
对于文本分类任务,输入可以是“classify: 这是一个很好的产品”,输出是“正面”;
对于翻译任务,输入可以是“translate English to French: How are you?”, 输出是“Comment ça va?”。
T5通过大规模的文本数据进行预训练,然后在具体任务上进行微调。这一过程与BERT、GPT等模型类似,但T5将预训练和微调阶段的任务统一为文本到文本的形式,使其在各种任务上的适应性更强。
我们可以通过图3.11,更加直观地理解 T5 的大一统思想:
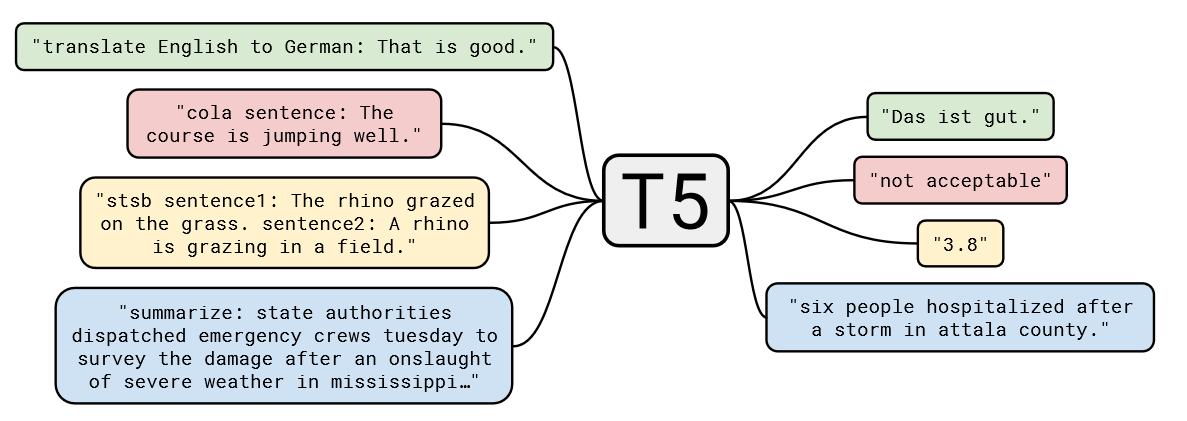
图3.11 T5 的大一统思想
对于不同的NLP任务,每次输入前都会加上一个任务描述前缀,明确指定当前任务的类型。这不仅帮助模型在预训练阶段学习到不同任务之间的通用特征,也便于在微调阶段迅速适应具体任务。例如,任务前缀可以是“summarize: ”用于摘要任务,或“translate English to German: ”用于翻译任务。
T5的大一统思想通过将所有NLP任务统一为文本到文本的形式,简化了任务处理流程,增强了模型的通用性和适应性。这一思想不仅推动了自然语言处理技术的发展,也为实际应用提供了更为便捷和高效的解决方案。
3.3 Decoder-Only PLM
在前两节中,我们分别讲解了由 Transformer 发展而来的两种模型架构——以 BERT 为代表的 Encoder-Only 模型和以 T5 为代表的 Encoder-Decoder 模型。那么,很自然可以想见,除了上述两种架构,还可以有一种模型架构——Decoder-Only,即只使用 Decoder 堆叠而成的模型。
事实上,Decoder-Only 就是目前大火的 LLM 的基础架构,目前所有的 LLM 基本都是 Decoder-Only 模型(RWKV、Mamba 等非 Transformer 架构除外)。而引发 LLM 热潮的 ChatGPT,正是 Decoder-Only 系列的代表模型 GPT 系列模型的大成之作。而目前作为开源 LLM 基本架构的 LLaMA 模型,也正是在 GPT 的模型架构基础上优化发展而来。因此,在本节中,我们不但会详细分析 Decoder-Only 代表模型 GPT 的原理、架构和特点,还会深入到目前的主流开源 LLM,分析它们的结构、特点,结合之前对 Transformer 系列其他模型的分析,帮助大家深入理解当下被寄予厚望、被认为是 AGI 必经之路的 LLM 是如何一步步从传统 PLM 中发展而来的。
首先,让我们学习打开 LLM 世界大门的代表模型——由 OpenAI 发布的 GPT。
3.3.1 GPT
GPT,即 Generative Pre-Training Language Model,是由 OpenAI 团队于 2018年发布的预训练语言模型。虽然学界普遍认可 BERT 作为预训练语言模型时代的代表,但首先明确提出预训练-微调思想的模型其实是 GPT。GPT 提出了通用预训练的概念,也就是在海量无监督语料上预训练,进而在每个特定任务上进行微调,从而实现这些任务的巨大收益。虽然在发布之初,由于性能略输于不久后发布的 BERT,没能取得轰动性成果,也没能让 GPT 所使用的 Decoder-Only 架构成为学界研究的主流,但 OpenAI 团队坚定地选择了不断扩大预训练数据、增加模型参数,在 GPT 架构上不断优化,最终在 2020年发布的 GPT-3 成就了 LLM 时代的基础,并以 GPT-3 为基座模型的 ChatGPT 成功打开新时代的大门,成为 LLM 时代的最强竞争者也是目前的最大赢家。
本节将以 GPT 为例,分别从模型架构、预训练任务、GPT 系列模型的发展历程等三个方面深入分析 GPT 及其代表的 Decoder-Only 模型,并进一步引出当前的主流 LLM 架构——LLaMA。
(1) 模型架构——Decoder Only
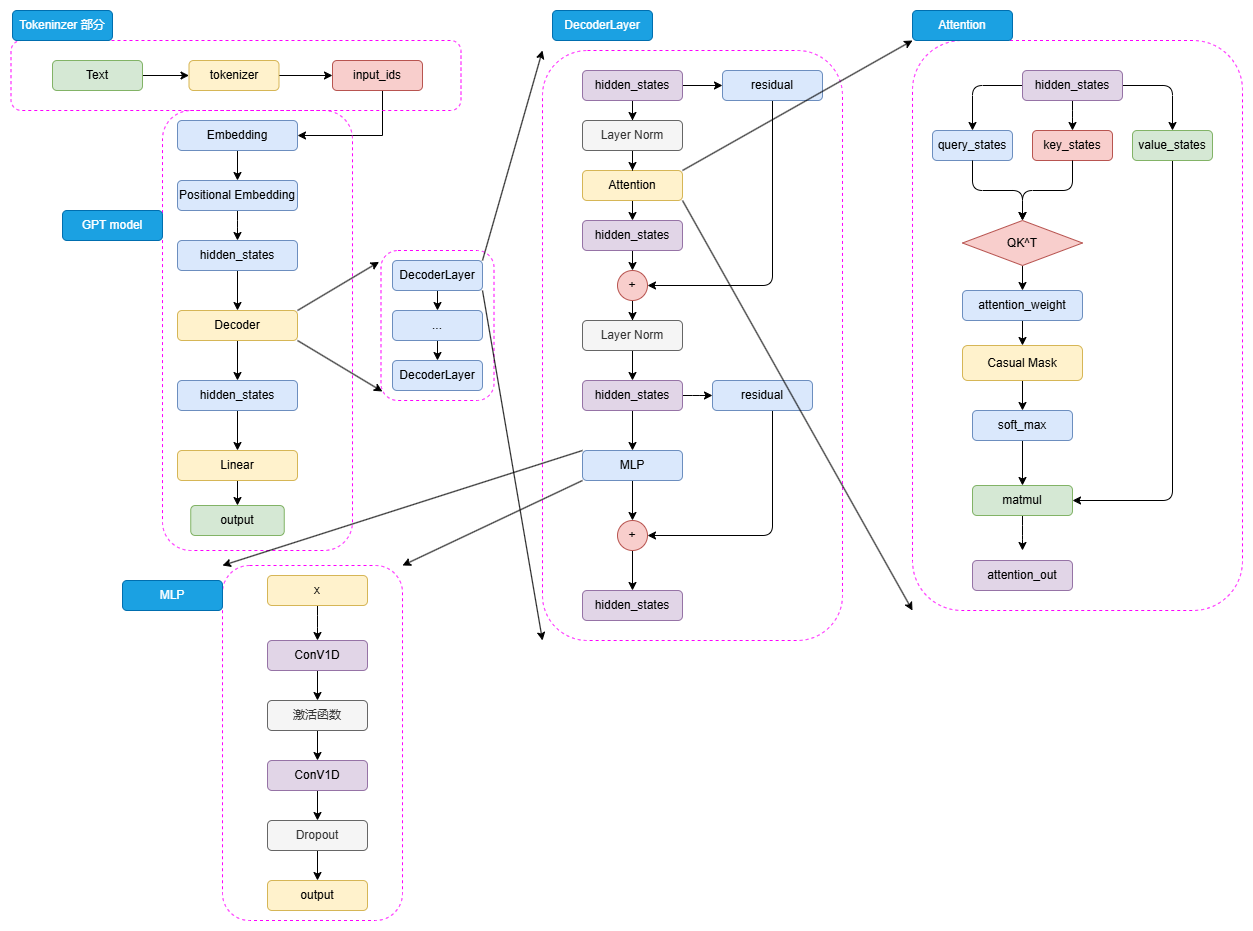
图3.12 GPT 模型结构
如图3.12可以看到,GPT 的整体结构和 BERT 是有一些类似的,只是相较于 BERT 的 Encoder,选择使用了 Decoder 来进行模型结构的堆叠。由于 Decoder-Only 结构也天生适用于文本生成任务,所以相较于更贴合 NLU 任务设计的 BERT,GPT 和 T5 的模型设计更契合于 NLG 任务和 Seq2Seq 任务。同样,对于一个自然语言文本的输入,先通过 tokenizer 进行分词并转化为对应词典序号的 input_ids。
输入的 input_ids 首先通过 Embedding 层,再经过 Positional Embedding 进行位置编码。不同于 BERT 选择了可训练的全连接层作为位置编码,GPT 沿用了 Transformer 的经典 Sinusoidal 位置编码,即通过三角函数进行绝对位置编码,此处就不再赘述,感兴趣的读者可以参考第二章 Transformer 模型细节的解析。
通过 Embedding 层和 Positional Embedding 层编码成 hidden_states 之后,就可以进入到解码器(Decoder),第一代 GPT 模型和原始 Transformer 模型类似,选择了 12层解码器层,但是在解码器层的内部,相较于 Transformer 原始 Decoder 层的双注意力层设计,GPT 的 Decoder 层反而更像 Encoder 层一点。由于不再有 Encoder 的编码输入,Decoder 层仅保留了一个带掩码的注意力层,并且将 LayerNorm 层从 Transformer 的注意力层之后提到了注意力层之前。hidden_states 输入 Decoder 层之后,会先进行 LayerNorm,再进行掩码注意力计算,然后经过残差连接和再一次 LayerNorm 进入到 MLP 中并得到最后输出。
由于不存在 Encoder 的编码结果,Decoder 层中的掩码注意力也是自注意力计算。也就是对一个输入的 hidden_states,会通过三个参数矩阵来生成 query、key 和 value,而不再是像 Transformer 中的 Decoder 那样由 Encoder 输出作为 key 和 value。后续的注意力计算过程则和 BERT 类似,只是在计算得到注意力权重之后,通过掩码矩阵来遮蔽了未来 token 的注意力权重,从而限制每一个 token 只能关注到它之前 token 的注意力,来实现掩码自注意力的计算。
另外一个结构上的区别在于,GPT 的 MLP 层没有选择线性矩阵来进行特征提取,而是选择了两个一维卷积核来提取,不过,从效果上说这两者是没有太大区别的。通过 N 个 Decoder 层后的 hidden_states 最后经过线性矩阵映射到词表维度,就可以转化成自然语言的 token,从而生成我们的目标序列。
(2)预训练任务——CLM
Decoder-Only 的模型结构往往更适合于文本生成任务,因此,Decoder-Only 模型往往选择了最传统也最直接的预训练任务——因果语言模型,Casual Language Model,下简称 CLM。
CLM 可以看作 N-gram 语言模型的一个直接扩展。N-gram 语言模型是基于前 N 个 token 来预测下一个 token,CLM 则是基于一个自然语言序列的前面所有 token 来预测下一个 token,通过不断重复该过程来实现目标文本序列的生成。也就是说,CLM 是一个经典的补全形式。例如,CLM 的输入和输出可以是:
input: 今天天气
output: 今天天气很
input: 今天天气很
output:今天天气很好
因此,对于一个输入目标序列长度为 256,期待输出序列长度为 256 的任务,模型会不断根据前 256 个 token、257个 token(输入+预测出来的第一个 token)...... 进行 256 次计算,最后生成一个序列长度为 512 的输出文本,这个输出文本前 256 个 token 为输入,后 256 个 token 就是我们期待的模型输出。
在前面我们说过,BERT 之所以可以采用预训练+微调的范式取得重大突破,正是因为其选择的 MLM、NSP 可以在海量无监督语料上直接训练——而很明显,CLM 是更直接的预训练任务,其天生和人类书写自然语言文本的习惯相契合,也和下游任务直接匹配,相对于 MLM 任务更加直接,可以在任何自然语言文本上直接应用。因此,CLM 也可以使用海量的自然语言语料进行大规模的预训练。
(3)GPT 系列模型的发展
自 GPT-1 推出开始,OpenAI 一直坚信 Decoder-Only 的模型结构和“体量即正义”的优化思路,不断扩大预训练数据集、模型体量并对模型做出一些小的优化和修正,来不断探索更强大的预训练模型。从被 BERT 压制的 GPT-1,到没有引起足够关注的 GPT-2,再到激发了涌现能力、带来大模型时代的 GPT-3,最后带来了跨时代的 ChatGPT,OpenAI 通过数十年的努力证明了其思路的正确性。
下表总结了从 GPT-1 到 GPT-3 的模型结构、预训练语料大小的变化:
GPT-1 是 GPT 系列的开山之作,也是第一个使用 Decoder-Only 的预训练模型。但是,GPT-1 的模型体量和预训练数据都较少,沿承了传统 Transformer 的模型结构,使用了 12层 Decoder Block 和 768 的隐藏层维度,模型参数量仅有 1.17亿(0.12B),在大小为 5GB 的 BooksCorpus 数据集上预训练得到。可以看到,GPT-1 的参数规模与预训练规模和 BERT-base 是大致相当的,但其表现相较于 BERT-base 却有所不如,这也是 GPT 系列模型没能成为预训练语言模型时代的代表的原因。
GPT-2 则是 OpenAI 在 GPT-1 的基础上进一步探究预训练语言模型多任务学习能力的产物。GPT-2 的模型结构和 GPT-1 大致相当,只是扩大了模型参数规模、将 Post-Norm 改为了 Pre-Norm(也就是先进行 LayerNorm 计算,再进入注意力层计算)。这些改动的核心原因在于,由于模型层数增加、体量增大,梯度消失和爆炸的风险也不断增加,为了使模型梯度更稳定对上述结构进行了优化。
GPT-2 的核心改进是大幅增加了预训练数据集和模型体量。GPT-2 的 Decoder Block 层数达到了48(注意,GPT-2 共发布了四种规格的模型,此处我们仅指规格最大的 GPT-2 模型),隐藏层维度达到了 1600,模型整体参数量达 15亿(1.5B),使用了自己抓取的 40GB 大小的 WebText 数据集进行预训练,不管是模型结构还是预训练大小都超过了 1代一个数量级。
GPT-2 的另一个重大突破是以 zero-shot(零样本学习)为主要目标,也就是不对模型进行微调,直接要求模型解决任务。例如,在传统的预训练-微调范式中,我们要解决一个问题,一般需要收集几百上千的训练样本,在这些训练样本上微调预训练语言模型来实现该问题的解决。而 zero-shot 则强调不使用任何训练样本,直接通过向预训练语言模型描述问题来去解决该问题。zero-shot 的思路自然是比预训练-微调范式更进一步、更高效的自然语言范式,但是在 GPT-2 的时代,模型能力还不足够支撑较好的 zero-shot 效果,在大模型时代,zero-shot 及其延伸出的 few-shot(少样本学习)才开始逐渐成为主流。
GPT-3 则是更进一步展示了 OpenAI“力大砖飞”的核心思路,也是 LLM 的开创之作。在 GPT-2 的基础上,OpenAI 进一步增大了模型体量和预训练数据量,整体参数量达 175B,是当之无愧的“大型语言模型”。在模型结构上,基本没有大的改进,只是由于巨大的模型体量使用了稀疏注意力机制来取代传统的注意力机制。在预训练数据上,则是分别从 CC、WebText、维基百科等大型语料集中采样,共采样了 45T、清洗后 570GB 的数据。根据推算,GPT-3 需要在 1024张 A100(80GB 显存)的分布式训练集群上训练 1个月。
之所以说 GPT-3 是 LLM 的开创之作,除去其巨大的体量带来了涌现能力的凸显外,还在于其提出了 few-shot 的重要思想。few-shot 是在 zero-shot 上的改进,研究者发现即使是 175B 大小的 GPT-3,想要在 zero-shot 上取得较好的表现仍然是一件较为困难的事情。而 few-shot 是对 zero-shot 的一个折中,旨在提供给模型少样的示例来教会它完成任务。few-shot 一般会在 prompt(也就是模型的输入)中增加 3~5个示例,来帮助模型理解。例如,对于情感分类任务:
zero-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0
few-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0。你可以参考以下示例来判断:‘你的表现非常好’——1;‘太糟糕了’——0;‘真是一个好主意’——1。
通过给模型提供少量示例,模型可以取得远好于 zero-shot 的良好表现。few-shot 也被称为上下文学习(In-context Learning),即让模型从提供的上下文中的示例里学习问题的解决方法。GPT-3 在 few-shot 上展现的强大能力,为 NLP 的突破带来了重要进展。如果对于绝大部分任务都可以通过人为构造 3~5个示例就能让模型解决,其效率将远高于传统的预训练-微调范式,意味着 NLP 的进一步落地应用成为可能——而这,也正是 LLM 的核心优势。
在 GPT 系列模型的基础上,通过引入预训练-指令微调-人类反馈强化学习的三阶段训练,OpenAI 发布了跨时代的 ChatGPT,引发了大模型的热潮。也正是在 GPT-3 及 ChatGPT 的基础上,LLaMA、ChatGLM 等模型的发布进一步揭示了 LLM 的无尽潜力。在下一节,我们将深入剖析目前 LLM 的普适架构——LLaMA。
3.3.2 LLaMA
LLaMA模型是由Meta(前Facebook)开发的一系列大型预训练语言模型。从LLaMA-1到LLaMA-3,LLaMA系列模型展示了大规模预训练语言模型的演进及其在实际应用中的显著潜力。
(1) 模型架构——Decoder Only
与GPT系列模型一样,LLaMA模型也是基于Decoder-Only架构的预训练语言模型。LLaMA模型的整体结构与GPT系列模型类似,只是在模型规模和预训练数据集上有所不同。如图3.13是LLaMA模型的架构示意图:
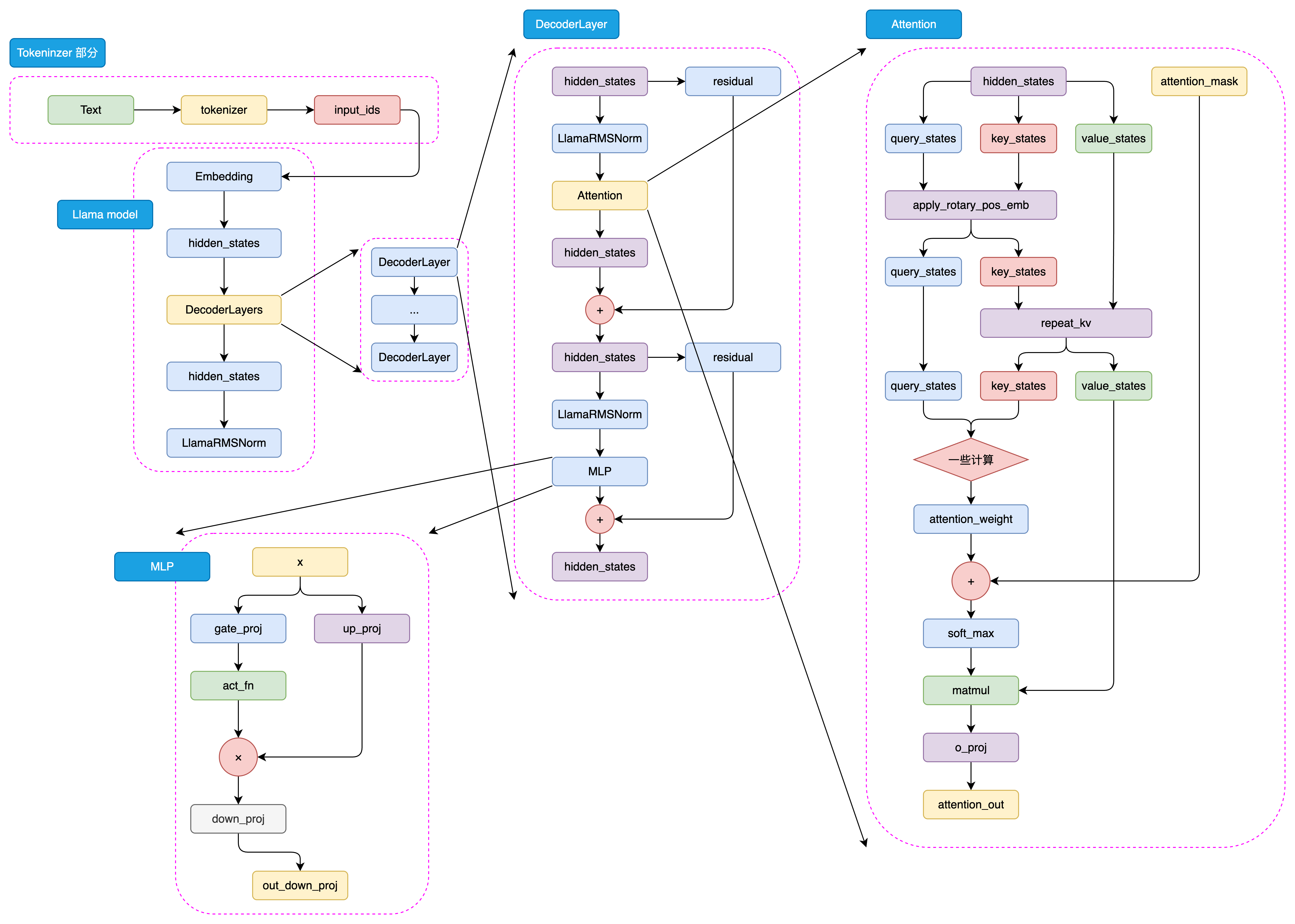
图3.13 LLaMA-3 模型结构
与GPT类似,LLaMA模型的处理流程也始于将输入文本通过tokenizer进行编码,转化为一系列的input_ids。这些input_ids是模型能够理解和处理的数据格式。接下来,这些input_ids会经过embedding层的转换,这里每个input_id会被映射到一个高维空间中的向量,即词向量。同时,输入文本的位置信息也会通过positional embedding层被编码,以确保模型能够理解词序上下文信息。
这样,input_ids经过embedding层和positional embedding层的结合,形成了hidden_states。hidden_states包含了输入文本的语义和位置信息,是模型进行后续处理的基础,hidden_states随后被输入到模型的decoder层。
在decoder层中,hidden_states会经历一系列的处理,这些处理由多个decoder block组成。每个decoder block都是模型的核心组成部分,它们负责对hidden_states进行深入的分析和转换。在每个decoder block内部,首先是一个masked self-attention层。在这个层中,模型会分别计算query、key和value这三个向量。这些向量是通过hidden_states线性变换得到的,它们是计算注意力权重的基础。然后使用softmax函数计算attention score,这个分数反映了不同位置之间的关联强度。通过attention score,模型能够确定在生成当前词时,应该给予不同位置的hidden_states多大的关注。然后,模型将value向量与attention score相乘,得到加权后的value,这就是attention的结果。
在完成masked self-attention层之后,hidden_states会进入MLP层。在这个多层感知机层中,模型通过两个全连接层对hidden_states进行进一步的特征提取。第一个全连接层将hidden_states映射到一个中间维度,然后通过激活函数进行非线性变换,增加模型的非线性能力。第二个全连接层则将特征再次映射回原始的hidden_states维度。
最后,经过多个decoder block的处理,hidden_states会通过一个线性层进行最终的映射,这个线性层的输出维度与词表维度相同。这样,模型就可以根据hidden_states生成目标序列的概率分布,进而通过采样或贪婪解码等方法,生成最终的输出序列。这一过程体现了LLaMA模型强大的序列生成能力。
(2) LLaMA模型的发展历程
LLaMA-1 系列:
Meta于2023年2月发布了LLaMA-1,包括7B、13B、30B和65B四个参数量版本。
这些模型在超过1T token的语料上进行了预训练,其中最大的65B参数模型在2,048张A100 80G GPU上训练了近21天。
LLaMA-1因其开源性和优异性能迅速成为开源社区中最受欢迎的大模型之一。
LLaMA-2 系列:
2023年7月,Meta发布了LLaMA-2,包含7B、13B、34B和70B四个参数量版本,除了34B模型外,其他均已开源。
LLaMA-2将预训练的语料扩充到了2T token,并将模型的上下文长度从2,048翻倍到了4,096。
引入了分组查询注意力机制(Grouped-Query Attention, GQA)等技术。
LLaMA-3 系列:
2024年4月,Meta发布了LLaMA-3,包括8B和70B两个参数量版本,同时透露400B的LLaMA-3还在训练中。
LLaMA-3支持8K长文本,并采用了编码效率更高的tokenizer,词表大小为128K。
使用了超过15T token的预训练语料,是LLaMA-2的7倍多。
LLaMA模型以其技术创新、多参数版本、大规模预训练和高效架构设计而著称。模型支持从7亿到数百亿不等的参数量,适应不同规模的应用需求。LLaMA-1以其开源性和优异性能迅速受到社区欢迎,而LLaMA-2和LLaMA-3进一步通过引入分组查询注意力机制和支持更长文本输入,显著提升了模型性能和应用范围。特别是LLaMA-3,通过采用128K词表大小的高效tokenizer和15T token的庞大训练数据,实现了在多语言和多任务处理上的重大进步。Meta对模型安全性和社区支持的持续关注,预示着LLaMA将继续作为AI技术发展的重要推动力,促进全球范围内的技术应用和创新。
3.3.3 GLM
GLM 系列模型是由智谱开发的主流中文 LLM 之一,包括 ChatGLM1、2、3及 GLM-4 系列模型,覆盖了指令理解、代码生成等多种应用场景,曾在多种中文评估集上达到 SOTA 性能。
ChatGLM-6B 是 GLM 系列的开山之作,也是 2023年国内最早的开源中文 LLM,也是最早提出不同于 GPT、LLaMA 的独特模型架构的 LLM。在整个中文 LLM 的发展历程中,GLM 具有独特且重大的技术意义。本节将简要叙述 GLM 系列的发展,并介绍其不同于 GPT、LLaMA 系列模型的独特技术思路。
(1)模型架构-相对于 GPT 的略微修正
GLM 最初是由清华计算机系推出的一种通用语言模型基座,其核心思路是在传统 CLM 预训练任务基础上,加入 MLM 思想,从而构建一个在 NLG 和 NLU 任务上都具有良好表现的统一模型。
在整体模型结构上,GLM 和 GPT 大致类似,均是 Decoder-Only 的结构,仅有三点细微差异:
使用 Post Norm 而非 Pre Norm。Post Norm 是指在进行残差连接计算时,先完成残差计算,再进行 LayerNorm 计算;而类似于 GPT、LLaMA 等模型都使用了 Pre Norm,也就是先进行 LayerNorm 计算,再进行残差的计算。相对而言,Post Norm 由于在残差之后做归一化,对参数正则化的效果更强,进而模型的鲁棒性也会更好;Pre Norm相对于因为有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失。因此,对于更大体量的模型来说,一般认为 Pre Norm 效果会更好。但 GLM 论文提出,使用 Post Norm 可以避免 LLM 的数值错误(虽然主流 LLM 仍然使用了 Pre Norm);
使用单个线性层实现最终 token 的预测,而不是使用 MLP;这样的结构更加简单也更加鲁棒,即减少了最终输出的参数量,将更大的参数量放在了模型本身;
激活函数从 ReLU 换成了 GeLUS。ReLU 是传统的激活函数,其核心计算逻辑为去除小于 0的传播,保留大于 0的传播;GeLUS 核心是对接近于 0的正向传播,做了一个非线性映射,保证了激活函数后的非线性输出,具有一定的连续性。
(2)预训练任务-GLM
GLM 的核心创新点主要在于其提出的 GLM(General Language Model,通用语言模型)任务,这也是 GLM 的名字由来。GLM 是一种结合了自编码思想和自回归思想的预训练方法。所谓自编码思想,其实也就是 MLM 的任务学习思路,在输入文本中随机删除连续的 tokens,要求模型学习被删除的 tokens;所谓自回归思想,其实就是传统的 CLM 任务学习思路,也就是要求模型按顺序重建连续 tokens。
GLM 通过优化一个自回归空白填充任务来实现 MLM 与 CLM 思想的结合。其核心思想是,对于一个输入序列,会类似于 MLM 一样进行随机的掩码,但遮蔽的不是和 MLM 一样的单个 token,而是每次遮蔽一连串 token;模型在学习时,既需要使用遮蔽部分的上下文预测遮蔽部分,在遮蔽部分内部又需要以 CLM 的方式完成被遮蔽的 tokens 的预测。例如,输入和输出可能是:
输入:I <MASK> because you <MASK>
输出:<MASK> - love you; <MASK> - are a wonderful person
通过将 MLM 与 CLM 思想相结合,既适配逐个 token 生成的生成类任务,也迫使模型从前后两个方向学习输入文本的隐含关系从而适配了理解类任务。使用 GLM 预训练任务产出的 GLM 模型,在一定程度上展现了其超出同体量 BERT 系模型的优越性能:
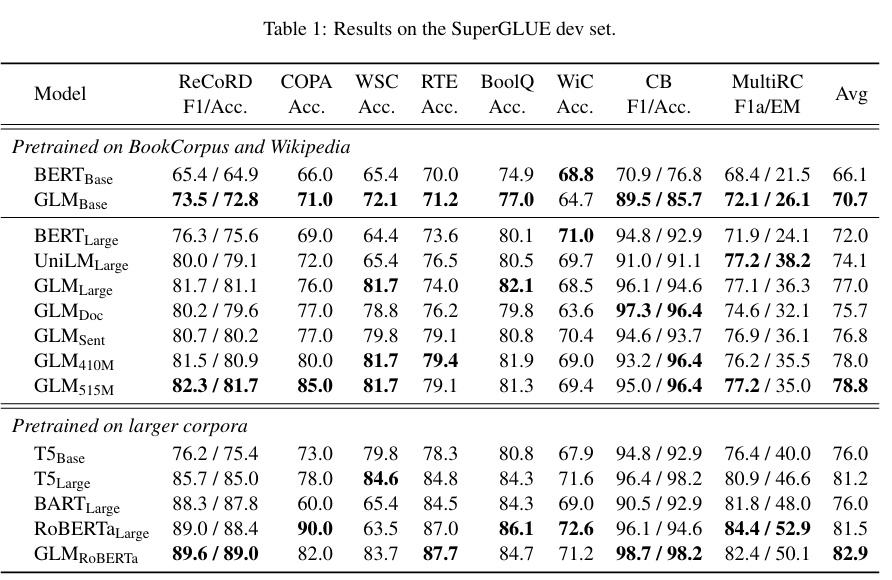
图3.14 alt text
不过,GLM 预训练任务更多的优势还是展现在预训练模型时代,迈入 LLM 时代后,针对于超大规模、体量的预训练,CLM 展现出远超 MLM 的优势。通过将模型体量加大、预训练规模扩大,CLM 预训练得到的生成模型在文本理解上也能具有超出 MLM 训练的理解模型的能力,因此,ChatGLM 系列模型也仅在第一代模型使用了 GLM 的预训练思想,从 ChatGLM2 开始,还是回归了传统的 CLM 建模。虽然从 LLM 的整体发展路径来看,GLM 预训练任务似乎是一个失败的尝试,但通过精巧的设计将 CLM 与 MLM 融合,并第一时间产出了中文开源的原生 LLM,其思路仍然存在较大的借鉴意义。
(3)GLM 家族的发展
在 GLM 模型(即使用原生 GLM 架构及预训练任务的早期预训练模型)的基础上,参考 ChatGPT 的技术思路进行 SFT 和 RLHF,智谱于 23年 3月发布了第一个中文开源 LLM ChatGLM-6B,成为了众多中文 LLM 研究者的起点。ChatGLM-6B 在 1T 语料上进行预训练,支持 2K 的上下文长度。
在 23年 6月,智谱就开源了 ChatGLM2-6B。相对于一代,ChatGLM2 将上下文长度扩展到了 32K,通过更大的预训练规模实现了模型性能的大幅度突破。不过,在 ChatGLM2 中,模型架构就基本回归了 LLaMA 架构,引入 MQA 的注意力机制,预训练任务也回归经典的 CLM,放弃了 GLM 的失败尝试。
ChatGLM3-6B 发布于 23年 10月,相对于二代在语义、数学、推理、代码和知识方面都达到了当时的 SOTA 性能,但是官方给出的技术报告说明 ChatGLM3 在模型架构上相对二代没有变化,最主要的优化来源是更多样化的训练数据集、更充足的训练步骤和更优化的训练策略。ChatGLM3 的另一个重要改进在于其开始支持函数调用与代码解释器,开发者可以直接使用开源的 ChatGLM3 来实现 Agent 开发,具有更广泛的应用价值。
2024年 1月,智谱发布了支持 128K 上下文,包括多种类型的 GLM-4 系列模型,评估其在英文基准上达到了 GPT-4 的水平。不过,智谱并未直接开源 GLM-4,而是开源了其轻量级版本 GLM-4-9B 模型,其在 1T token 的多语言语料库上进行预训练,上下文长度为 8K,并使用与 GLM-4 相同的管道和数据进行后训练。在训练计算量较少的情况下,其超越了 Llama-3-8B,并支持 GLM-4 中所有工具的功能。
图3.15展示了 GLM 系列模型在基准集上的表现演进:
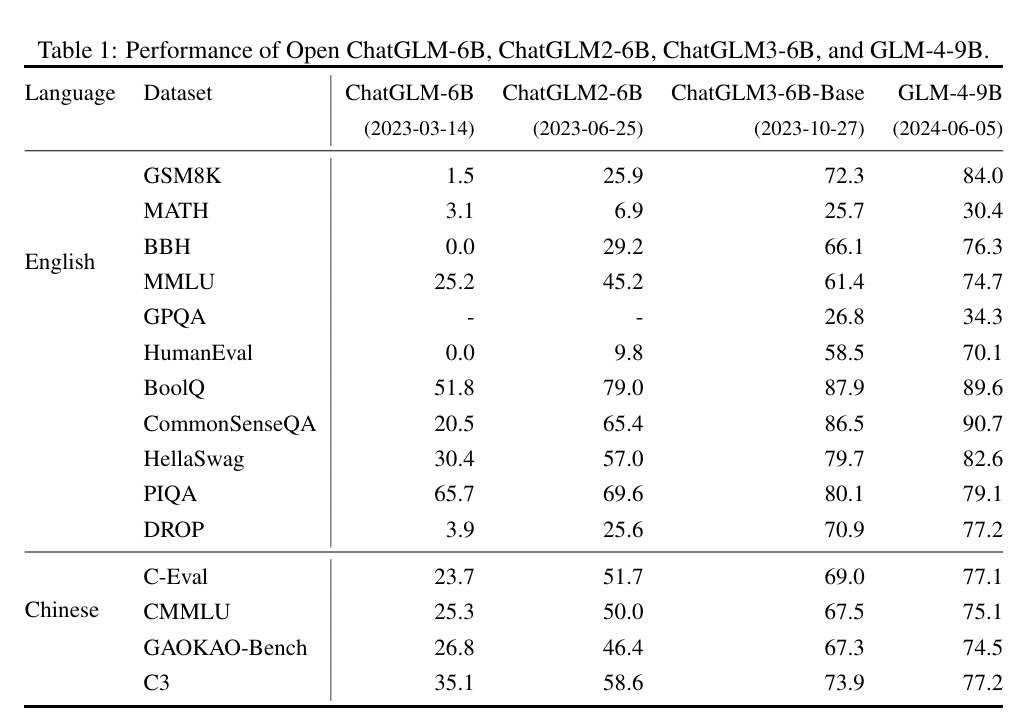
图3.15 alt text
参考资料
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
[2] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[3] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut. (2020). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.
[4] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. (2023). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683.
[5] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 21(140), 1–67.
[6] Alec Radford, Karthik Narasimhan. (2018). Improving Language Understanding by Generative Pre-Training. Retrieved from https://api.semanticscholar.org/CorpusID:49313245
[7] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
[8] 张帆, 陈安东的文章“万字长文带你梳理Llama开源家族:从Llama-1到Llama-3”,来源:https://mp.weixin.qq.com/s/5_VnzP3JmOB0D5geV5HRFg
[9] Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Jingyu Sun, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiao Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yifan An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhen Yang, Zhengxiao Du, Zhenyu Hou, and Zihan Wang. (2024). ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv preprint arXiv:2406.12793.
[10] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang 和 Jie Tang. (2022). GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv preprint arXiv:2103.10360.
评论区